


语义分割的U-Net网络结构Unet是2015年诞生的模型,它几乎是当前segmentation项目中应用最广的模型。Unet能从更少的训练图像中进行学习,当它在少于40张图的生物医学数据集上训练时,IOU值仍能达到92%。Unet网络非常简单,前半部分作用是特征提取,后半部分是上采样。在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
论文链接: https://arxiv.org/pdf/1505.04597v1.pdf
github: https://github.com/milesial/Pytorch-UNet
1 Motivation
生物医学图像处理面临的问题
- 经典卷积网络大部分都是针对图像分类任务的,但是在一些特定场景,如医疗图像处理领域,应是pixel-wise像素级的处理,输入输出均是图像,即图像分割。
- 生物医学任务中没有很多标注的数据集
为了解决这两个问题,Ciresan用滑窗法来预测patch的类别(patch指像素周围的局部区域)。 该算法有两个主要问题:(1)由于每个patch都需要训练导致这个算法很慢,且patch之间有很多重复。(2)定位准确率和上下文联系之间需要平衡,patch越大需要pooling越多准确率越低,patch越小则不具备上下文联系。
2 U-Net网络
作者以FCN全卷积神经网络为基础设计了Unet,其中包含两条串联的路径:contracting path用来提取图像特征,捕捉context,将图像压缩为由特征组成的feature maps;expanding path用来精准定位,将提取的特征解码为与原始图像尺寸一样的分割后的预测图像。
和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,FCN用的是加操作(sum),U-Net用的是叠操作(concat)。最重要的是编码和解码(encoder-decoder)的思路,编码和解码常用于压缩图像和去噪声,后来这个思路被用在了图像分割上,非常简洁好用。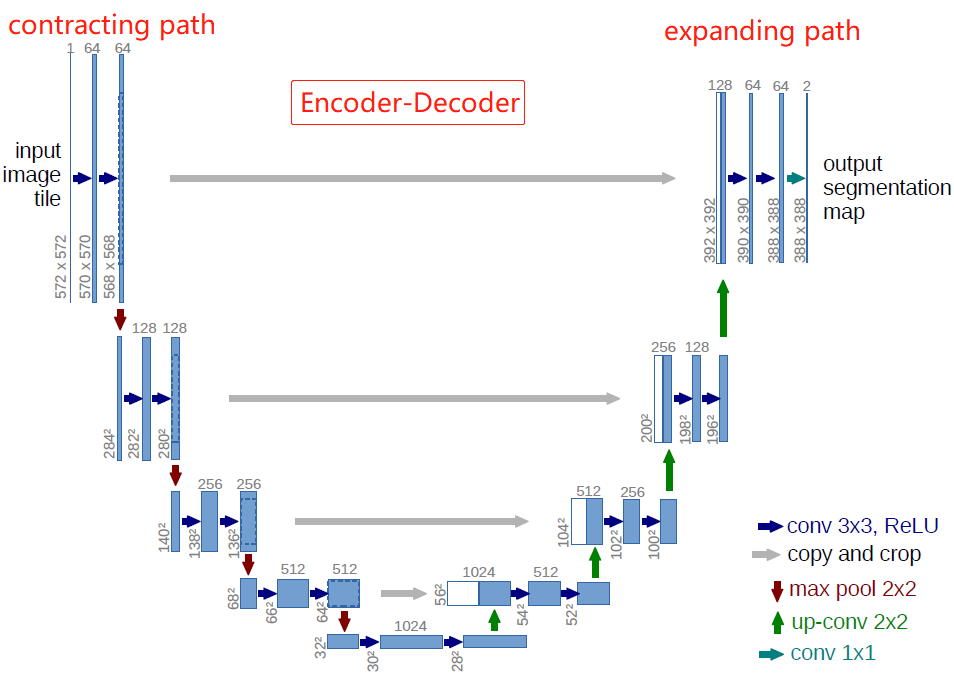
- 网络左边一侧作者称之为contracting path,右边一侧为expanding path。
- 蓝色箭头为卷积层,卷积层的stride=1,padding=0,因此卷积后特征层的宽高会减2。卷积层后接ReLU激活函数,没有BN层(BN由Google于2015年提出)。
- 池化层stride=2,池化后宽高减半,通道数不变。池化层之后的卷积层将通道数翻倍。
- 绿色的up-conv是转置卷积,将特征层的宽高×2,通道数减半。
- 灰色copy and crop是先对左边的特征层进行中心裁剪(保留中心特征),再与右边path对应的特征层进行通道数上的concat。
- 最后的1×1的卷积没有ReLU,输出通道数为类别数。
Overlap-tile

可以发现Unet论文中输入的图像是572×572,但是输出图像大小为388×388。也就是说推理上图黄色部分,需要蓝色区域内的图像数据作为输入。当黄色区域位于边缘时,就会产生边缘数据缺失的情况(上图右边蓝框中的空白部分)。我们可以在预处理中,对输入图像进行padding,通过padding扩大输入图像的尺寸,使得最后输出的结果正好是原始图像的尺寸,同时输入图像块(黄框)的边界也获得了上下文信息从而提高预测的精度,本文用的是mirror padding。我们自己搭建网络的时候,输入输出往往是一样大小的(padding=1),因此不需要考虑这个问题。
3 训练
3.1 数据增强
网络需要大量标注训练样本,生物医学任务中没有数千个标注的数据集,所以需要对数据进行数据扩张。作者采用了弹性变形的图像增广,以此让网络学习更稳定的图像特征。因为数据集是细胞组织的图像,细胞组织的边界每时每刻都会发生不规则的畸变,所以这种弹性变形的增广是非常有效的。论文笔记:图像数据增强之弹性形变(Elastic Distortions)
3.2 损失函数的权重
细胞组织图像的一大特点是,多个同类的细胞会紧紧贴合在一起,其中只有细胞壁或膜组织分割。因此,作者在计算损失的过程中,给两个细胞的边缘部分及细胞间的背景部分增加了损失的权重,以此让网络更加注重这类重合的边缘信息。
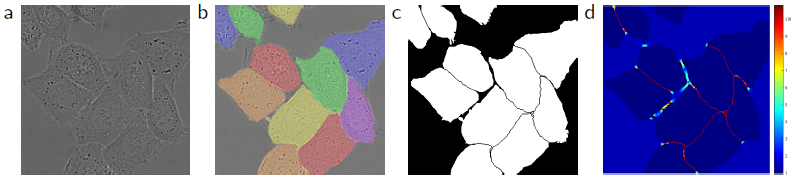
如上图所示,图(a)为原始图像,图(b)为人工标注的实例分割ground truth,图(c)为mask,图(d)为每个像素的损失权重weight map。首先用形态学操作获得边界,再用下面的公式计算weight map
![]()
其中,wc是为了类别平衡,d1是该像素到最近细胞边界的距离,d2是到第二近的细胞边界的距离。在作者实验中设置w0=10,σ≈5pixels.
3.3 其他
- 优化器:SGD + momentum(0.99)
- batch:为了最大限度的使用GPU显存,比起输入一个大的batch size,更倾向于大量输入tiles,因此实验batch size为1。
- 损失函数:pixel-wise softmax + cross_entropy
- 初始化高斯分布权重:在具有许多卷积层和通过网络的不同路径的深度网络中,权重的良好初始化非常重要。 否则,网络的某些部分可能会进行过多的激活,而其他部分则永远不会起作用。 理想情况下,应调整初始权重,以使网络中的每个特征图都具有大约单位方差。作者用的高斯分布的权重。
参考
1. 精读论文U-Net
2. 论文笔记:图像数据增强之弹性形变(Elastic Distortions)
3. 研习U-Net



评论区