


丢失数据的本质
在本文开始前,首先明白一个点,平时我们说的组件数据不丢失究竟是在指什么,如果你往ES写入数据,ES返回给你写入错误,这个不算数据丢失。如果你往ES写入数据,ES返回给你成功,但是后续因为ES节点重启或宕机导致写入的数据不见了,这个才叫数据丢失。
简而言之,丢失数据的本质是ES本身搞丢了返回结果是成功写入的数据。
数据写入流程
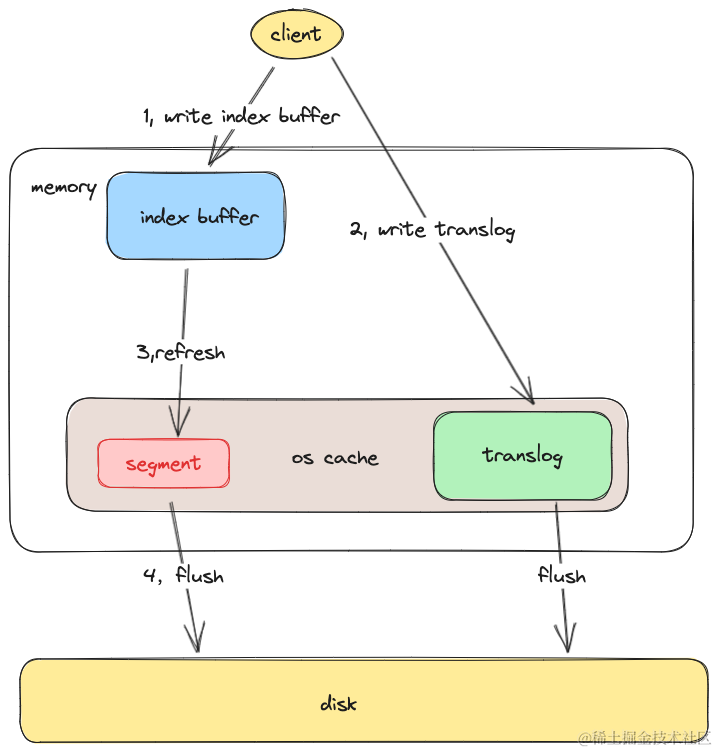
1,写入时,ES会首先往一块内存缓存中写入数据,这快内存缓存在ES中叫index buffer,此时数据是不可见的,只有经过refresh操作后,数据才能变得可见。
index buffer的大小设置可以通过 下面的请求去进行设置,如下,设置了index buffer的大小为总内存的30%
PUT /_cluster/settings
{
"persistent" : {
"indices.memory.index_buffer_size" : "30%"
}
}
2, 在写入index buffer成功后,会写translog 记录写入的数据。此时数据依然不可见。由于操作系统对文件写入,并不会立即落盘。所以ES提供了关于刷盘的配置,index.translog.durability两个选项值,如下,
request会在每次创建segment写入数据后就对translog进行刷盘操作。async则会定时对translog进行刷盘操作。定时刷新到磁盘的周期是通过index.translog.sync_interval参数去进行控制,默认是5s。
3,refresh 操作可以主动触发也可以定时触发,默认是1s会进行一次, 该操作会创建一个lucece的segment段用于存储新写入到index buffer中的数据,注意这里即使写入到了segment里,数据还是在os Cache系统文件系统缓存中,并没有落入磁盘,只有 在lucece将数据 commit 到磁盘后,数据才能落盘。
4, 在文件系统缓存中的segment总归还是要写入磁盘,默认每30分钟,或者当translog的日志量达到某个量级时,segment会进行落盘,同时删掉translog日志。这个量级由index.translog.flush_threshold_size 去进行控制,默认是512mb。
在了解了ES的写入数据的过程后,我们可以发现,如果将index.translog.durability 设置为request ,这样便能让每次请求返回客户端成功时,保证一定会有translog日志存储到磁盘上,后续如果在系统缓存中的segment因为系统宕机而没有落盘依然能够通过translog去进行恢复。
而如果index.translog.durability 设置为 async 则有可能会丢失5s的数据。



评论区