


Homework4
Dataset介绍及处理
Dataset introduction
训练数据集metadata.json包括speakers和n_mels,前者表示每个speaker所包含的多条语音信息(每条信息有一个路径feature_path和改条信息的长度mel_len或理解为frame数即可),后者表示滤波器数量,简单理解为特征数即可,由此可知每个.pt语言文件可以表示为大小为mel_len \(\times\) n_mels的矩阵,其中所有文件已规定n_mels为40,不同的是语言信息的长度即mel_len。
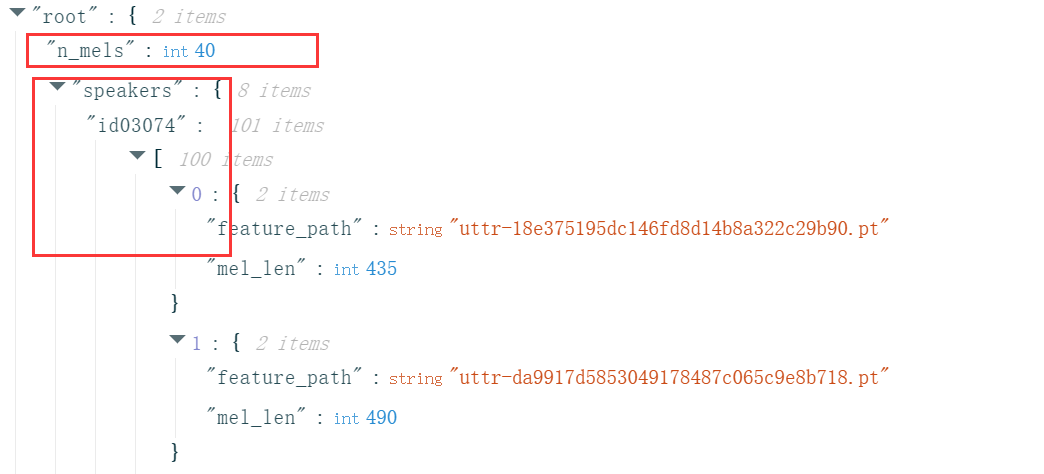
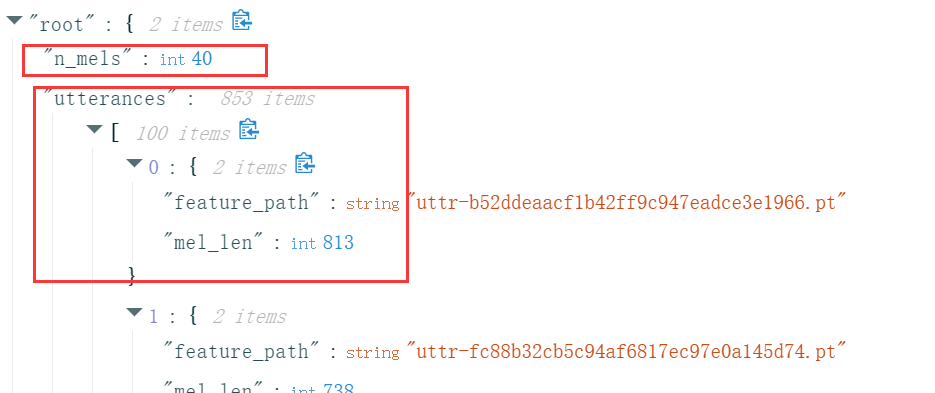
测试数据集testdata.json包括n_mels和utterances,其中n_mels和意义前面一样且固定为40,utterance表示一条语音信息,不同的是这里我们不知道这则信息是谁说出来的,任务就是检测这些信息分别是谁说的。
映射文件mapping.json包括两项speaker2id和id2speaker,前者将600个speaker的编号隐射为0-599,后者则是相反的操作。

Dataset procession
正如上面说,尽管“古圣先贤”已经帮我们做好了绝大多数的数据处理操作,但是如果想要批量训练数据那么就需要对每个语音序列的mel_len进行固定,比如在sample code里面固定为128个frame
class myDataset(Dataset):
def __init__(self, data_dir, segment_len=128):
它的具体实现方式如下
def __getitem__(self, index):
feat_path, speaker = self.data[index]
# Load preprocessed mel-spectrogram.
mel = torch.load(os.path.join(self.data_dir, feat_path))
# Segmemt mel-spectrogram into "segment_len" frames.
if len(mel) > self.segment_len:
# Randomly get the starting point of the segment.
start = random.randint(0, len(mel) - self.segment_len)
# Get a segment with "segment_len" frames.
mel = torch.FloatTensor(mel[start:start+self.segment_len])
else:
mel = torch.FloatTensor(mel)
# Turn the speaker id into long for computing loss later.
speaker = torch.FloatTensor([speaker]).long()
return mel, speaker
即从每个语音序列总的frame中抽取连续的128个frame,但是这并不能够保证所有的语音需要都为128个frame,可能某语音序列的frame数原本就小于128,因此还需要另外一道保险即padding。
def collate_batch(batch):
# Process features within a batch.
"""Collate a batch of data."""
mel, speaker = zip(*batch)
# Because we train the model batch by batch, we need to pad the features in the same batch to make their lengths the same.
mel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad log 10^(-20) which is very small value.
# mel: (batch size, length, 40)
return mel, torch.FloatTensor(speaker).long()
def get_dataloader(data_dir, batch_size, n_workers):
"""Generate dataloader"""
dataset = myDataset(data_dir)
speaker_num = dataset.get_speaker_number()
# Split dataset into training dataset and validation dataset
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
trainset, validset = random_split(dataset, lengths)
train_loader = DataLoader(
trainset,
batch_size=batch_size,
shuffle=True,
drop_last=True,
num_workers=n_workers,
pin_memory=True,
collate_fn=collate_batch,
)
valid_loader = DataLoader(
validset,
batch_size=batch_size,
num_workers=n_workers,
drop_last=True,
pin_memory=True,
collate_fn=collate_batch,
)
return train_loader, valid_loader, speaker_num
在data_loader读取一个batch时,如果仍旧有不同大小的frame,那么就可以通过指定collate_fn=collate_batch对数据进行填充,确保每个batch的frame相同进而进行批量(并行?)计算。
当然你也可以不预先设置frame数为128,仅使用collate_batch,那么就会使这个batch内所有语音序列的frame数自动对齐到最长的frame,但往往会爆显存。
Self-Attention简单介绍
在不考虑Multi-Head Attention以及add &norm的情况下
\(X'=\)Self-Attention\((X, W^q, W^k, W^v, W^l)\) = \(\frac{XW^q(XW^k)^T}{\sqrt{d_k}}XW^vW^l\)
其中\(X, W^q, W^k, W^v, W^l\)维度分别为\(n\times d_{model}, d_{model}\times d_k, d_{model}\times d_k, d_{model}\times d_v, d_v\times d_{model}\),并称\(Q=X\times W^q, K = X\times W^k, V = X\times W^v\)
可知,变化后的\(X'\)与原来\(X\)的维度相同,这一变化过程简称为编码,那么问题来了\(X'\)与\(X\)究竟有何不同?
在变化过程中,我们对\(Q\)和\(K\)做了内积运算,这表示一个查询匹配过程,内积越大则相似度越高,那么匹配所得的权重也就越大(表明越关注这个讯息),之后再和\(V\)运算相当于通过前面的权重及原始\(V\)对新\(X\)的\(V\)做预测,视频给出了很生动的表述。
但是这里我有一疑问,为什么点积运算可以表示关注度?点积可以在一定程度表示两向量的关联性,这一点毫无疑问,但是凭什么关联性越高也意味着关注度(得分)越高呢?



评论区