


Numpy其实是最早的处理数据的Python库,它的核心ndarray对象,是一个高效的n维数组结构。
通过这个库,可以高效的完成向量和矩阵运算,由于其出色的性能,很多其他的数据分析,科学计算或者机器学习相关的Python库都或多或少的依赖于它。
Pandas就是其中之一,Pandas充分利用了NumPy的数组运算功能,使得数据处理和分析更加高效。
比如,Pandas中最重要的两个数据结构Series和DataFrame在内部就使用了NumPy的ndarray来存储数据。
在使用Pandas进行数据分析的过程中,按条件检索和过滤数据是最频繁的操作。
本文介绍两种通过结合Numpy,一方面让Pandas的检索过滤代码更加简洁易懂,另一方面还能保障检索过滤的高性能。
1. 准备数据
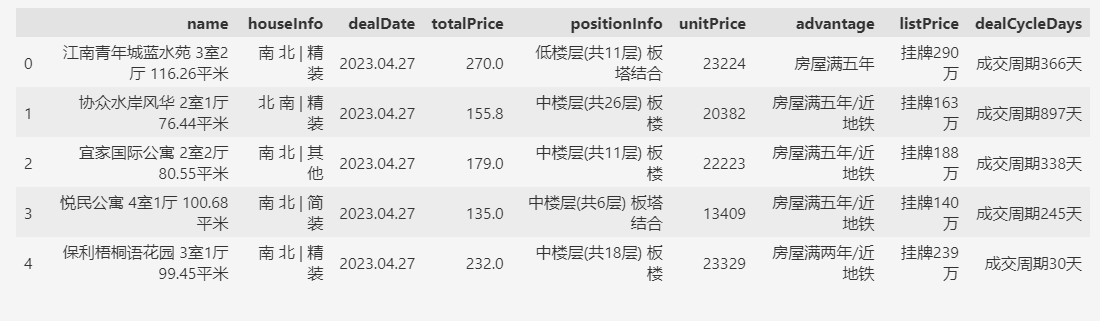
第一步,先准备数据,这次使用二手房交易数据,可从 https://databook.top/lianjia/nj 下载。
import pandas as pd
import numpy as np
# 这个路径替换成自己的路径
fp = r'D:\data\南京二手房交易\南京江宁区.csv'
df = pd.read_csv(fp)
df.head()
2. 一般条件判断(np.where)
比如,买房前我们想先分析下已有的成交信息,对于房价能有个大致的印象。
下面,按照总价和单价,先挑选总价200~300万之间,或者单价1万以下的成交信息。
符合条件返回“OK”,否则返回“NG”。
def filter_data(row):
if row["totalPrice"] > 200 and row["totalPrice"] < 300:
return "OK"
if row["unitPrice"] < 10000:
return "OK"
return "NG"
df["评估"] = df.apply(filter_data, axis=1)
df[df["评估"] == "OK"].head()
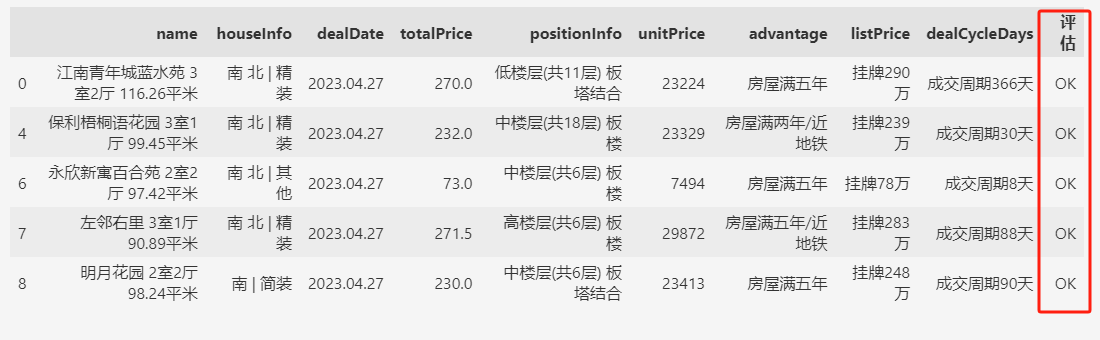
上面的过滤数据写法是使用Pandas时用的比较多的方式,也就是将过滤条件封装到一个自定义函数(filter_data)中,然后通过 apply 函数来完成数据过滤。
下面我们用Numpy的 np.where 接口来改造上面的代码。np.where类似Python编程语言中的if-else判断,基本语法:
import numpy as np
np.where(condition[, x, y])
其中:
- condition:条件表达式,返回布尔数组。
- x 和 y:可选参数,
condition为True,返回x,反之,返回y。
如果未提供x 和 y,则函数仅返回满足条件的元素的索引。
改造后的代码如下:
# 根据单价过滤
cond_unit_price = np.where(
df["unitPrice"] < 10000,
"OK",
"NG",
)
# 先根据总价过滤,不满足条件再用单价过滤
cond_total_price = np.where(
(df["totalPrice"] > 200) & (df["totalPrice"] < 300),
"OK",
cond_unit_price,
)
df["评估"] = cond_total_price
df[df["评估"] == "OK"].head()
运行之后返回的结果是一样的,但是性能提升很多。
如果数据量是几十万量级的话,你会发现改造之后的代码运行效率提高了几百倍。
3. 复杂多条件判断(np.select)
上面的示例中,判断还比较简单,属于if-else,也就是是与否的判断。
下面设计一种更复杂的判断,将成交信息评估为“优良中差”4个等级,而不仅仅是“OK”和“NG”。
我们假设:
- 优:房屋精装,且位于中楼层,且近地铁
- 良:总价<300,且近地铁
- 中:总价<400
- 差:其他情况
用传统的方式,同样是封装一个类似filter_data的函数来判断“优良中差”4个等级,然后用 apply 函数来完成数据过滤。
这里就不演示了,直接看结合Numpy的np.select接口,高效的完成“优良中差”4个等级的过滤。
np.select类似Python编程语言中的match匹配,基本语法:
numpy.select(condlist, choicelist, default=0)
其中:
- condlist:条件列表,每个条件都是一个布尔数组。
- choicelist:与 condlist 对应的数组列表,当某个条件为真时,返回该位置对应的数组中的元素。
- default:可选参数,当没有条件为真时返回的默认值。
# 设置 “优,良,中” 的判断条件
conditions = [
df["houseInfo"].str.contains("精装")
& df["positionInfo"].str.contains("中楼层")
& df["advantage"].str.contains("近地铁"),
(df["totalPrice"] < 300) & df["advantage"].str.contains("近地铁"),
df["totalPrice"] < 400,
]
choices = ["优", "良", "中"]
# 默认为 “差”
df["评估"] = np.select(conditions, choices, default="差")
df.head()
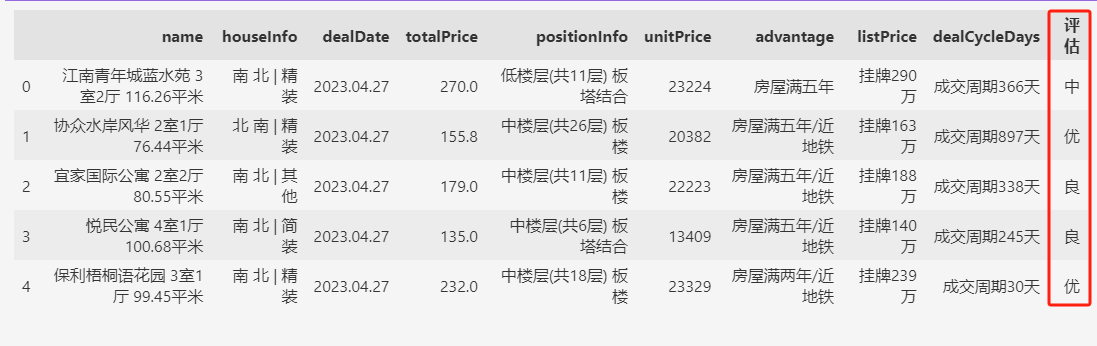
这样,就实现了一个对成交信息的分类。
4. 总结
np.where 和 np.select的底层都是向量化的方式来操作数据,执行效率非常高。
所以,我们在使用Pandas分析数据时,应尽量使用np.where 和 np.select来帮助我们过滤数据,这样不仅能够让代码更加简洁专业,而且能够极大的提高分析性能。



评论区