


完整代码及其数据,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote
前言
在python机器学习笔记:深入学习决策树算法原理一文中我们提到了决策树里的ID3算法,C4.5算法,并且大概的了解了CART算法。对于ID3算法的实战可参考这篇文章(python机器学习笔记:ID3决策树算法实战)。虽然我们已经对于C4.5算法也有了粗略的了解,并且提到了其不足,比如模型是用较为复杂的熵度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归问题等等。但是对于这些问题CART算法又做了相应的改进。不同于C4.5 ,CART本质是对特征空间进行二元划分(即CART生成的决策树是一颗二叉树),并能够对标量属性(nominal attribute)与连续属性(continuous attribute)进行分裂。所以本文就学习一下CART算法。
CART也是决策树的一种,不过是满二叉树,CART可以是强分类器,就跟决策树一样,但是我们可以指定CART的深度,使之成为比较弱的分类器,CART生成过程和决策树类似,也是采用递归划分的,不过也存在很多的不同之处。
本文学习CART(Classification And Regression Trees,分类回归树)树构建算法。该算法是由Leo Breiman,Jerome Friedman,Richard Olshen与Charles Stone于1984年提出,即可以用于分类也可以用于回归,其数据的建模方法为二元切分法,因此非常值得学习。下面我们利用Python来构建并显示CART树,代码会保持足够的灵活性以便能用于多个问题当中。接着,利用CART算法构建回归树并介绍其中的树剪枝技术(该技术的主要目的是防止树的过拟合)。之后引入了一个更高级的模型树算法。与回归树的做法(在每个叶节点上使用各自的均值做预测)不同,该算法需要在每个叶子节点上都构建出一个线性模型。在这些树的构建算法中有一些需要调整的参数。
1,复杂数据的局部性建模问题
前面ID3决策树算法实战 博文里面我们学习了使用决策树来进行分类。决策树不断将数据切分成小数据集,直到所有目标变量完全相同,或者数据不能再切分为止。但是决策树也是一种贪心算法啊,它要在给定时间内做出最佳选择,但并不关心能否达到全局最优。所以ID3 决策树算法存在以下问题:
首先,ID3的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说,如果一个特征有4种取值,那么数据被切成4份。一旦按某特征切分后,该特征在之后的算法执行过程中将不会再起作用,所以有观点认为这种切分方式过于迅速。另外一种方法是二元切分法,即每次把数据集切成两份。如果数据的某特征值等于切分所要求的值,那么这些数据就进入了树的左子树,反之则进入树的右子树。
除了切分过于迅速外,ID3算法还存在另一个问题,它不能直接处理连续型特征。只有事先将连续型特征转换成离散型,才能在ID3算法中使用。但这种转换过程会破坏连续型变量的内在性质。而使用二元切分法则易于树构建过程进行调整以处理连续型特征。具体的处理方法是:如果特征值大于给定值就走左子树,否则走右子树。另外,二元切分法也节省了树的构建时间,但这点意义也不是特别大,因为这些树构建一般是离线完成,时间并非需要重点关注的因素。
CART是十分著名且广泛记载的树构建算法,它使用二元切分来处理连续型变量。对CART稍作修改就可以处理回归问题,前面ID3使用香农熵来度量集合的无组织程序。如果选用其他方法来代替香农熵,就可以使用树构建算法来完成回归。
2,CART算法与C4.5, ID3的对比
CART算法相比C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。当然CART树的最大的好处是还可以做回归模型,下面给出ID3,C4.5, CART算法的一个比较总结(来自:https://www.cnblogs.com/pinard/p/6053344.html)
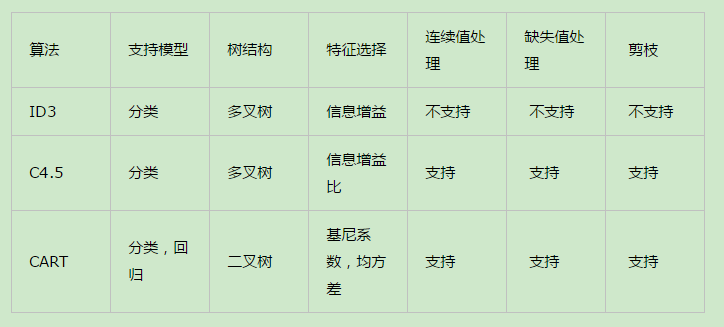
下面,我们总结一下决策树,这里不再纠结于ID3, C4.5 和 CART的区别什么的。我们来看看决策树算法作为一个大类别的分类回归算法的优缺点。
2.1 决策树的优点
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是 O(log2m)。m为样本数
4)既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
5)可以处理多维度输出的分类问题。
6)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
7)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
8) 对于异常点的容错能力好,健壮性高。
2.2 决策树的缺点
1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
1,CART分类树算法
1.1 CART分类算法原理
上面提到过,在ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。在C4.5算法中,采用了信息增益比来选择特征,以减少信息增益容易选择特征多的特征的问题。但是无论是ID3还是C4.5都是基于信息论的熵模型,这里面会涉及大量的对数运算。能不能简化模型的同时也不至于完全丢失熵模型的优点呢?
这里要说的CART算法就是,CART分类树使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。
具体的,在分类问题中,假设有K个类别,第K个类别的概率为Pk,则概率分布的基尼指数定义为:
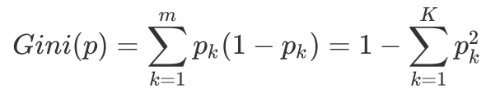
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是P,则基尼系数的表达式为:
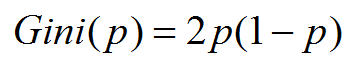
对于给定的样本D,假设有K个类别,第K个类别的数量为Ck,则样本D的基尼系数表达式为:
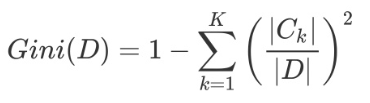
特别的,对于样本D,如果根据特征A的某个值 a在数据集D上进行分割,把D分为D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为:
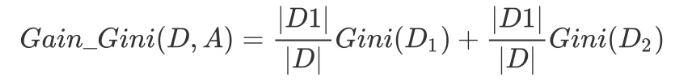
其中基尼系数Gini(D) 表示集合D的不确定性,基尼系数Gini(D,A)表示 A=a 分割后集合D的不确定性。基尼指数越大,样本集合的不确定性越大。
对于属性A,分别计算任意属性值将数据集划分为两部分之后的Gain_Gini,选取其中的最小值,作为属性A得到的最优二分方案。然后对于训练集S,计算所有属性的最优二分方案,选取其中的最小值,作为样本集S的最优二分方案
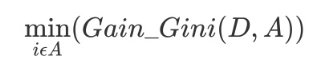
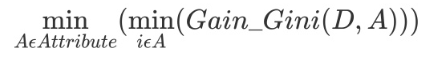
我们可以比较下基尼系数表达式和熵模型的表达式,二次运算是不是比对数简单很多?尤其是二分类的计算更加简单,但是简单归简单,和熵模型的度量方式比,基尼系数对应的误差有多大呢?对于二类分类,基尼系数和熵之半的曲线如下:
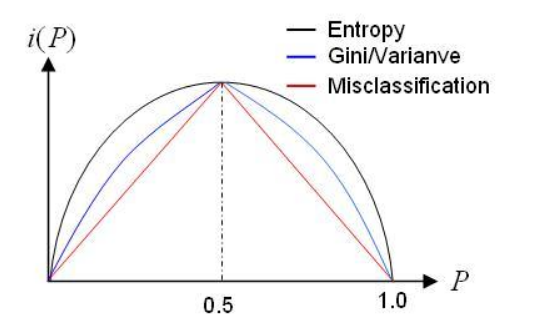
从上图可看出,基尼系数和熵之半的曲线非常接近,仅仅在45度角附近误差稍大。因此,基尼系数可以作为熵模型的一个近似替代。而CART分类树算法就是使用的基尼系数来选择决策树的特征。同时,为了进一步简化,CART分类树算法每次仅仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树。这样一可以进一步简化基尼系数的计算,二可以建立一个更加优雅的二叉树模型。
1.2 CART分类树实例详解
数据如下:
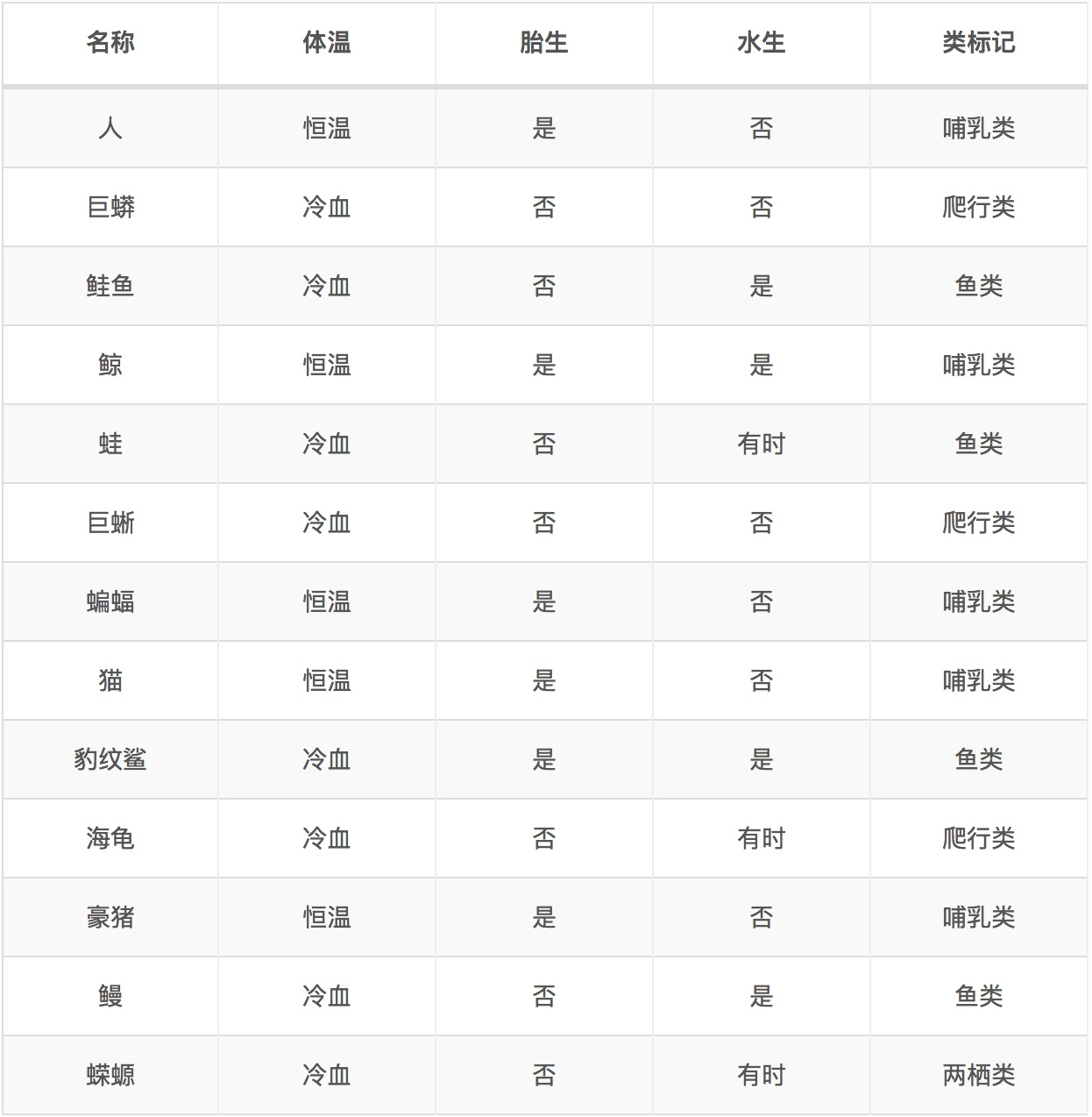
上述离散型数据,按照体温为恒温和非恒温进行划分,其中恒温包括哺乳类5个,鸟类2个,非恒温时包括爬行类3个,鱼类3个,两栖类2个。
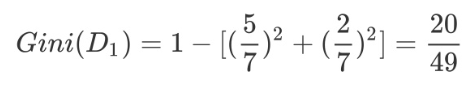
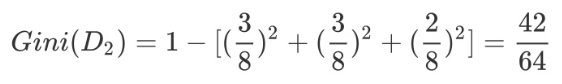
然后计算得到特征体温下数据集的 Gini指数,最后我们选择 Gain_Gini最小的特征和相应的划分:

1.3 CART分类树算法对于连续特征和离散特征处理的改进
对于CART分类树连续值的处理问题,其思想和C4.5是相同的,都是将连续的特征离散化。唯一的区别在于在选择划分点时的度量方式不同,C4.5使用的是信息增益比,则CART分类树使用的是基尼系数。
具体的思路如下:比如有 m个样本的连续特征A有m个,从小到大排列为 a1, a2, ... am,则CART算法取相邻两样本值的平均数,一共取得 m-1 个划分点,其中第 i个划分点 Ti 表示为 Ti = (ai+ai+1)/2 。 对于这 m-1个点,分别计算以该店作为二元分类点时的基尼系数。选择基尼系数最小的点作为该连续特征的二元离散分类点。比如取到的基尼系数最小的点为 at,则小于at 的值为类别1,大于at 的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与ID3或者C4.5 处理离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
对于CART分类树离散值的处理问题,采用的思路是不停的二分离散特征。
回忆下ID3或者C4.5,如果某个特征A被选取建立决策树节点,如果它有A1,A2,A3三种类别,我们会在决策树上一下建立一个三叉的节点。这样导致决策树是多叉树。但是CART分类树使用的方法不同,他采用的是不停的二分,还是这个例子,CART分类树会考虑把A分成 {A1} 和 {A2, A3},{A2}和{A1, A3}, {A3}和{A1, A2} 三种情况,找到基尼系数最小的组合,比如{A2}和{A1, A3},然后建立二叉树节点,一个节点是A2对应的样本,另一个节点是{A1,A3}对应的节点。同时,由于这次没有把特征A的取值完全分开,后面我们还有机会在子节点继续选择到特征A来划分A1和A3。这和ID3或者C4.5不同,在ID3或者C4.5的一棵子树中,离散特征只会参与一次节点的建立。
2,CART 回归树算法
2.1 CART回归树算法原理
CART回归树预测回归连续型数据,假设X与Y分别是输入和输出变量,并且Y是连续变量。在巡逻数据集所在的输入空间中,递归的将每个区间划分为两个子区间并决定每个子区域上的输出值,构建二叉决策树。
选择最优切分变量 j 与切分点 s:遍历变量 j,对规定的切分变量 j 扫描切分点 s,选择使下式得到最小值的(j, s)对。其中 Rm是被划分的输入空间,cm是空间Rm对应的固定输出值。

用选定的(j, s)对,划分区域并决定相应的输出值
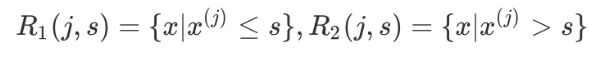
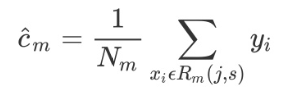
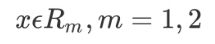
继续对两个子区域调用上述步骤,将输入空间划分为 M 个区域 R1, R2.....Rm,生成决策树。
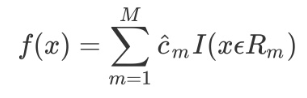
当输入空间划分确定时,可以用平方误差来表示回归树对训练数据的预测方法,用平方误差最小的准则求解每个单元上的最优输出值。
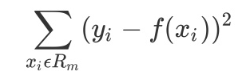
2.2 CART回归树算法实例详解
数据如下:

考虑如上所示的连续型变量,根据给定的数据点,考虑 1.5, 2.5, 3.5, 4.5,5.5, 6.5, 7.5, 8.5, 9.5 切分点,对各切分点依次求出R1, R2, c1, c2以及 m(s),例如当切分点 s=1.5 时,得到 R1={1} R2={2, 3, 4, 5, 6, 7, 8, 9, 10},其中c1, c2, m(s) 如下所示:

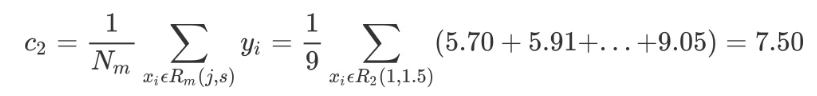
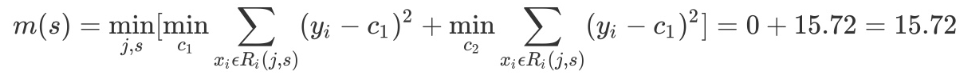
依次改变(j , s)对,可以得到 s 以及 m(s) 的计算结果,如下表所示:

当 x=6.5 时,此时 R1={1, 2, 3, 4, 5, 6} R2={7, 8, 9, 10} c1=6.24 c2=8.9。回归树T1(x)为:

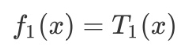
然后我们利用 f1(x) 拟合训练数据的残差,如下表所示

用 f1(x) 拟合训练数据得到平方误差
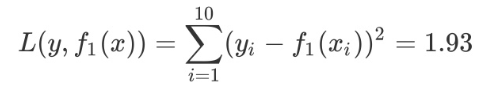
第二步求 T2(x)与 求T1(x) 方法相同,只是拟合的数据是上表的残差。可以得到
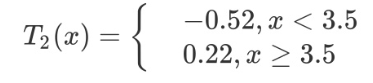
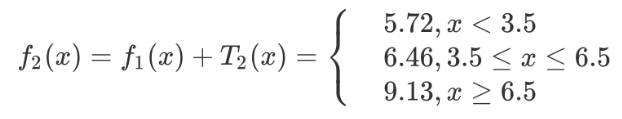
用 f2(x) 拟合训练数据的平方误差
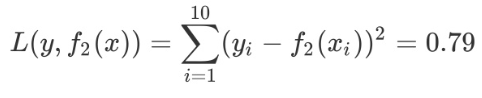
继续求得 T3(x), T4(x), T5(x), T6(x),如下所示:

用f6(x)拟合训练数据的平方损失误差如下所示,假设此时已经满足误差要求,那么f(x)=f6(x)便是所求的回归树。
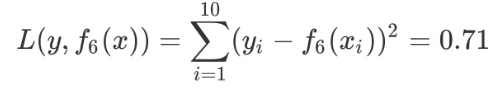
2.3 CART剪枝
我们将一颗充分生长的树称为 T0,希望减少树的大小来防止过拟合。但是同时去掉一些节点后预测的误差可能会增大,那么如何达到这两个变量之间的平衡则是问题的关键。因此我们用一个变量 α 来平衡,定义损失函数如下:

- T为任意子树,|T| 为子树 T 的叶子节点个数
- α 是参数,权衡拟合程度与树的复杂度
- C(T) 为预测误差,可以是平方误差也可以是基尼指数,C(T) 衡量训练数据的拟合程度
那么我们如何找到这个合适的 α 来使拟合程度与复杂度之间达到最好的平衡呢?准确的方法就是将 α 从 0 取到正无穷,对于每个固定的 α ,我们都可以找到使得Cα(T) 最小的最优子树T(α)
- 当 α 很小的时候,T0是这样的最优子树
- 当α很大的时候,单独一个根节点就是最优子树
尽管 α 的取值无限多,但是T0的子树是有限个,Tn是最后剩下的根结点,子树生成是根据前一个子树Ti,剪掉某个内部节点后,生成Ti+1。然后对折页的子树序列分别用测试集进行交叉验证,找到最优的那个子树作为我们的决策树。子树序列如下:
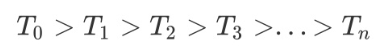
因此CART剪枝分为两部分,分别是生成子树序列和交叉验证。
下面将实现CART算法回归树。回归树与分类树的思路类似,但是叶子节点的数据类型不是离散型,而是连续型。
2.3.1 树回归的一般方法
- (1)收集数据:采用任意方法收集数据
- (2)准备数据:需要数值型的数据,标称型数据应该映射成二值型数据
- (3)分析数据:汇出数据的二维可视化显示结果,以字典方式生成树
- (4)训练算法:大部分时间都花费在叶子节点数模型的构建上
- (5)测试算法:使用测试数据上的R2值来分析模型的效果
- (6)使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
2.4 CART生成原理
2.4.1 特征选择
CART分类树预测分类离散型数据,采用基尼指数选择最优特征,同时决定该特征的最优二值切分点。CART对特征属性进行二元分裂。特别的,当特征属性为标量或者连续时,可选择如下方式分裂:
An instance goes left if CONDITION ,and goes right otherwise
即样本记录满足CONDITION则分裂给左子树,否则分裂给右子树。
2.4.2 标量属性
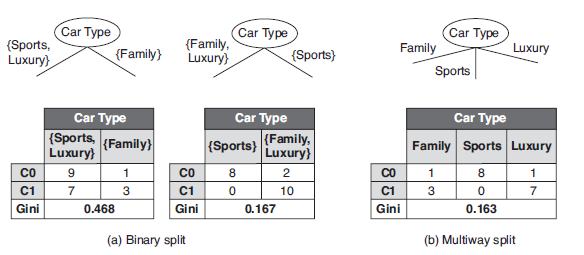
进行分裂的CONDITION可置为不等于属性的某值;比如,标量属性Car Type取值空间为{Sports, Fanily, Luxury},二元分裂与多路分裂如下:
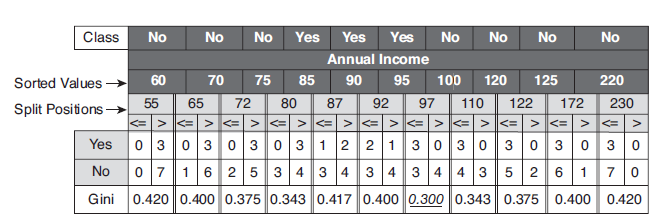
连续属性:CONDITION可以设置为不大于ε ;比如,连续属性Annual Income,ε 取属性相邻值的平均值,其二元分裂结果如下:
接下来,需要解决的问题:应该选择哪种特征属性及定义CONDITION,才能分类效果比较好,CART采用Gini指数来度量分裂时的不纯度,之所以采用Gini指数,是因为较于熵而言计算速度更快一些。对于决策树的节点t,Gini指数计算公式如下:
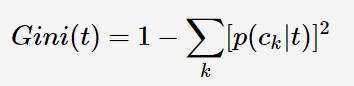
Gini指数即为1与类别Ck的概率平方之和的差值,反映了样本集合的不确定性程序。Gini指数越大,样本集合的不确定性程度越高。分类学习过程的本质是样本不确定性程序的减少(即熵减过程),故应选择最小Gini指数的特征分裂。父节点对应的样本集合为D,CART选择特征A分裂为两个子节点,对应集合为DL与DR;分裂后的Gini指数定义如下:
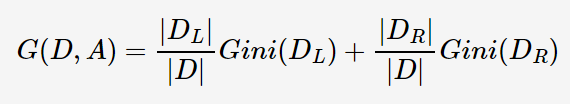
其中|.| 表示样本集合的记录数量,如上图的表格所示,当Annual Income 的分裂值取87时,则Gini指数计算如下:
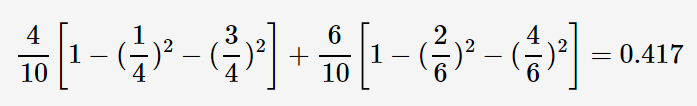
3,sklearn CART算法
scikit-learn决策树算法库内部实现的时使用了调优过的 CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
3.1 DecisionTree Classifier重要参数
首先我们看看其库里的决策树都有哪些参数:
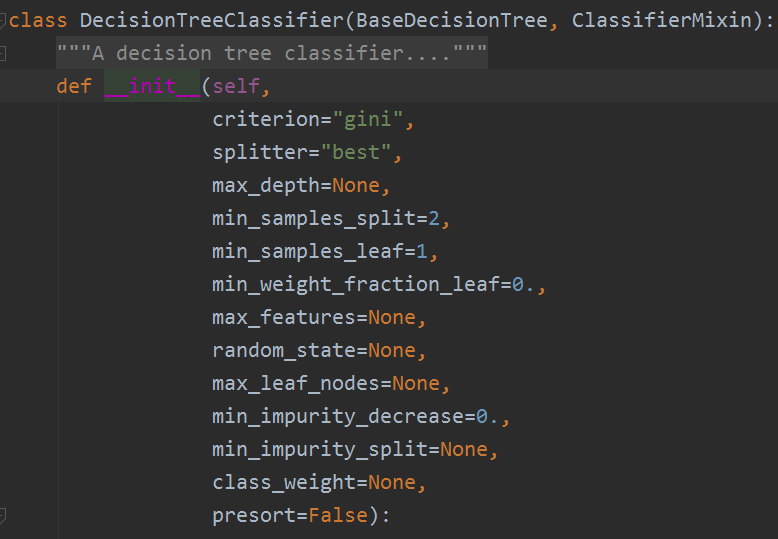
为了便于比较,这里我们使用表格对其重要的参数进行展示,并学习其意义
-
1.criterion gini or entropy 前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数 gini就可以了,即CART算法,除非你更喜欢类似于ID3, C4.5 的最优特征选择方法
-
2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候),默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random"
-
3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
-
4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
-
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
-
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
-
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
-
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
-
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
-
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
-
n_estimators:要建立树的个数
3.2 DecisionTree Classifier调参注意点
1)当样本少数量但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
2)如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
3)推荐多用决策树的可视化(下节会讲),同时先限制决策树的深度(比如最多3层),这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
4)在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
5)决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
6)如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
3.3 决策树可视化环境搭建
scikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
第一步是安装graphviz。下载地址在:http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH
(注意:这里一定要在window上加上自己的路径,不然找不到)
第二步是安装python插件graphviz: pip install graphviz
第三步是安装python插件pydotplus: pip install pydotplus
这样环境就搭好了,有时候python会很笨,仍然找不到graphviz,这时,可以在代码里面加入这一行:
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
注意后面的路径是你自己的graphviz的bin目录。
3.4 决策树可视化——iris案例
我们以sklearn中 iris 数据作为训练集,iris属性特征包括花萼长度、花萼宽度、花瓣长度、花瓣宽度,类别共三类,分别为Setosa、Versicolour、Virginca。
代码如下:
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
# load data
iris = load_iris()
X = iris.data
y = iris.target
clf = tree.DecisionTreeClassifier()
clf.fit(X, y)
# export_graphviz support a variety of aesthetic options
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.view()
生成的效果图如下:
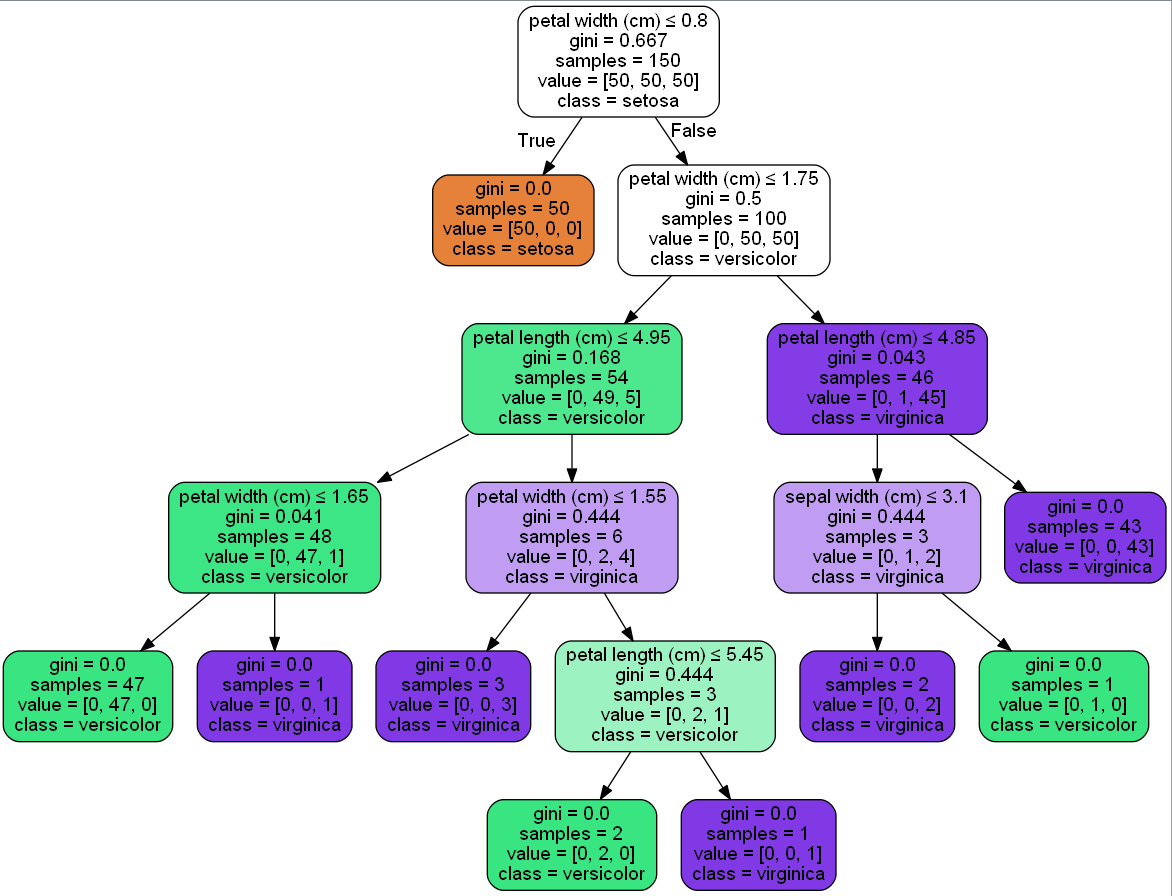
还可以使用刘建平老师的限制决策树层数为4的决策树例子:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
# 仍然使用自带的iris数据
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
# 训练模型,限制树的最大深度4
clf = DecisionTreeClassifier(max_depth=4)
#拟合模型
clf.fit(X, y)
# 画图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.show()
得到的图如下:

参考文献:https://www.cnblogs.com/en-heng/p/5035945.html
https://www.cnblogs.com/pinard/p/6056319.html
https://www.zhihu.com/search?type=content&q=CART%E5%88%86%E7%B1%BB%E6%A0%91
https://www.cnblogs.com/pinard/p/6053344.html
《机器学习实战》



评论区