


难点:
- 如何拆词?如何定义分隔符?
- 匹配的优先级是什么?
关键点:
- 有限自动机
- 元素拆分
解析 age >= 45
为了入门字词是如何拆分识别的,我们举一个最简单的例子age >= 45
- 只有三种类型:标识符(age)、大于号(GE)、数字字面量(IntLiteral)
- 使用空格分隔不同的元素
思路:
- 从左到右依次读取字符串
- 使用有限自动机,根据读到的字符进行状态转换,状态机如下
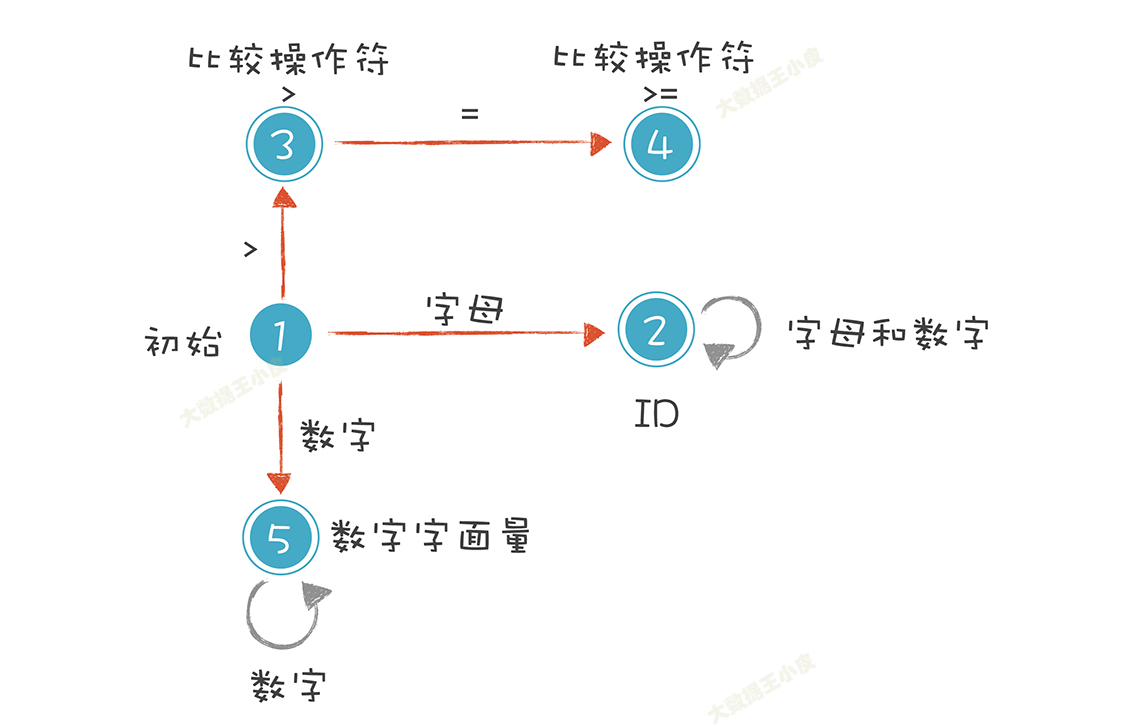
先上代码,理解一下上述过程,也可以调试进去看看执行的逻辑是什么样的。
SimpleToken.java
/**
* Token的一个简单实现。只有类型和文本值两个属性。
*/
public final class SimpleToken implements Token {
//Token类型
public TokenType type = null;
//文本值
public String text = null;
@Override
public TokenType getType() {
return type;
}
@Override
public String getText() {
return text;
}
}
public interface Token{
public TokenType getType();
public String getText();
}
SimpleTokenReader
public class SimpleTokenReader implements TokenReader {
List<Token> tokens = null;
int pos = 0;
public SimpleTokenReader(List<Token> tokens) {
this.tokens = tokens;
}
@Override
public Token read() {
if (pos < tokens.size()) {
return tokens.get(pos++);
}
return null;
}
@Override
public Token peek() {
if (pos < tokens.size()) {
return tokens.get(pos);
}
return null;
}
@Override
public void unread() {
if (pos > 0) {
pos--;
}
}
@Override
public int getPosition() {
return pos;
}
@Override
public void setPosition(int position) {
if (position >=0 && position < tokens.size()){
pos = position;
}
}
}
public interface TokenReader{
public Token read();
public Token peek();
public void unread();
public int getPosition();
public void setPosition(int position);
}
MyLexer.java
public class MyLexer {
private StringBuffer tokenText = null; //临时保存token的文本
private List<Token> tokens = null; //保存解析出来的Token
private SimpleToken token = null; //当前正在解析的Token
public static void main(String[] args) {
MyLexer lexer = new MyLexer();
String script = "age >= 45";
System.out.println("parse: " + script);
SimpleTokenReader tokenReader = lexer.tokenize(script);
dump(tokenReader);
}
//是否是字母
private boolean isAlpha(int ch) {
return ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z';
}
//是否是数字
private boolean isDigit(int ch) {
return ch >= '0' && ch <= '9';
}
//是否是空白字符
private boolean isBlank(int ch) {
return ch == ' ' || ch == '\t' || ch == '\n';
}
// 有限状态机的各种状态。
private enum DfaState {
Initial,
Id, GT, GE,
IntLiteral
}
/**
* 有限状态机进入初始状态。
* 这个初始状态其实并不做停留,它马上进入其他状态。
* 开始解析的时候,进入初始状态;某个Token解析完毕,也进入初始状态,在这里把Token记下来,然后建立一个新的Token。
*/
private DfaState initToken(char ch) {
if (tokenText.length() > 0) {
token.text = tokenText.toString();
tokens.add(token);
tokenText = new StringBuffer();
token = new SimpleToken();
}
DfaState newState = DfaState.Initial;
if (isAlpha(ch)) { //第一个字符是字母
newState = DfaState.Id; //进入Id状态
token.type = TokenType.Identifier;
tokenText.append(ch);
} else if (isDigit(ch)) { //第一个字符是数字
newState = DfaState.IntLiteral;
token.type = TokenType.IntLiteral;
tokenText.append(ch);
} else if (ch == '>') { //第一个字符是>
newState = DfaState.GT;
token.type = TokenType.GT;
tokenText.append(ch);
} else {
newState = DfaState.Initial; // skip all unknown patterns
}
return newState;
}
/**
* 解析字符串,形成Token。
* 这是一个有限状态自动机,在不同的状态中迁移。
* @param code
* @return
*/
public SimpleTokenReader tokenize(String code) {
tokens = new ArrayList<Token>();
CharArrayReader reader = new CharArrayReader(code.toCharArray());
tokenText = new StringBuffer();
token = new SimpleToken();
int ich = 0;
char ch = 0;
DfaState state = DfaState.Initial;
try {
while ((ich = reader.read()) != -1) {
ch = (char) ich;
switch (state) {
case Initial:
state = initToken(ch); //重新确定后续状态
break;
case Id:
if (isAlpha(ch) || isDigit(ch)) {
tokenText.append(ch); //保持标识符状态
} else {
state = initToken(ch); //退出标识符状态,并保存Token
}
break;
case GT:
if (ch == '=') {
token.type = TokenType.GE; //转换成GE
state = DfaState.GE;
tokenText.append(ch);
} else {
state = initToken(ch); //退出GT状态,并保存Token
}
break;
case IntLiteral:
if (isDigit(ch)) {
tokenText.append(ch); //继续保持在数字字面量状态
} else {
state = initToken(ch); //退出当前状态,并保存Token
}
break;
default:
}
}
// 把最后一个token送进去
if (tokenText.length() > 0) {
initToken(ch);
}
} catch (IOException e) {
e.printStackTrace();
}
return new SimpleTokenReader(tokens);
}
public static void dump(SimpleTokenReader tokenReader){
System.out.println("text\ttype");
Token token = null;
while ((token= tokenReader.read())!=null){
System.out.println(token.getText()+"\t\t"+token.getType());
}
}
}
不难理解,对吧。
无非就是在 tokenize 函数中挨个读取字符串,根据上面自动机实现的逻辑。
遇到分隔字符(如空格)就会触发 initToken 将前面读取到的字符和类型进行保存。
你可能会有疑问:
搞这么复杂干什么?按空格切分然后再字符串匹配不就行了?
确实可以实现,使用这种方式实现还更简单,但是我们想要做的是一个更通用的处理逻辑。
如果按照提议的方式,对于更复杂的字符串(比如不是空格分隔、空格不一定是分隔符、关键字保留等)那就需要更多的人工逻辑来处理,而且会越来越复杂和难以扩展,很可能一个特例导致需要推倒重来。



评论区