


Part.1 引入
当你遇到一个区间询问但是难以用线段树等 log 算法维护的时候怎么办?那就是——莫队!
莫队这个东西能支持区间修改、区间查询的操作,但是这种算法要求离线。莫队有很多种,详细请看下文。
Part.2 普通莫队
我们先来看一道例题(P1972 的削弱版):
给你一个长度为 \(n\) 的序列 \(a\),\(m\) 次查询,询问区间 \([l,r]\) 有多少个不同的数。
数据范围:\(1\le n,m\le 10^5,1\le a_i\le 10^5\)。
普通的暴力就是每次遍历这个区间,拿个桶记一下,每次需要清空桶。
发现每次清空桶十分浪费,所以可以考虑从上一次的询问区间伸缩过来。就是记一个 \(tl,tr\),初始为 \(tl=1,tr=0\)。每次把 \(tl\) 往 \(l\) 上靠,把 \(tr\) 往 \(r\) 上靠。代码如下:
//add(x) 是加入下标为 x 的数,del(x) 是减去下标为 x 的数,这两个函数视情况而定
while(tl>l) add(--tl);
while(tr<r) add(++tr);
while(tl<l) del(tl++);
while(tr>r) del(tr--);
当然这不是莫队,他是可以被卡的(大小区间交替询问,移动的量级就变成 \(nm\))。
莫队,就是通过离线后对询问左右端点排序,达到降低复杂度的目的。
先讲做法,记一个块长 \(B = \sqrt n\),然后以 \(\lfloor\frac{l}{B}\rfloor\) 为第一关键字,\(r\) 为第二关键字,从小到大排序。这样处理完所有询问的时间复杂度上界为 \(O(n\sqrt n)\)。
为啥这样能保证时间复杂度呢?为了方便,我们定义点 \(i\) 在编号为 \(\lfloor{\frac{i}{B}}\rfloor\) 的块内。不妨设 \(n,m\) 同阶。考虑两种情况:
- 上一个左端点和当前处理的左端点在一个块内:那么左端点最多移动 \(B\) 次,总共就只有 \(nB\) 次;询问左端点在一个块内的右端点是单调递增的,所以一个块内至多移动 \(n\) 次,而最多有 \(\lceil\frac{n}{B}\rceil\) 个块,所以总询问次数是 \(\lceil\frac{n}{B}\rceil n\);
- 上一个左端点和当前处理的左端点不在一个块内:左端点最多移动 \(2B\) 次,右端点也只移动 \(n\) 次,所以这部分的移动次数就只有 \(2B\lceil\frac{n}{B}\rceil+\lceil\frac{n}{B}\rceil n\)。
平均一下,当 \(B\) 取 \(\sqrt n\) 时,时间复杂度就是 \(O(n\sqrt n)\)。
给出上面例题的代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6+5;
int n,m,a[N],cnt[N],res,ans[N],B;
struct node{
int l,r,id;
inline void init(int x){cin>>l>>r,id = x;}
inline bool friend operator < (node x,node y)//重载运算符,相当于写一个 cmp
{
if(x.l/B!=y.l/B) return x.l<y.l;
return x.r<y.r;
}
}q[N];
inline void add(int x)
{
x = a[x];
cnt[x]++;
if(cnt[x]==1) res++;
}
inline void del(int x)
{
x = a[x];
cnt[x]--;
if(!cnt[x]) res--;
}
signed main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>n;
B = sqrt(n);
for(int i = 1;i<=n;i++)
cin>>a[i];
cin>>m;
for(int i = 1;i<=m;i++)
q[i].init(i);
sort(q+1,q+m+1);
int l = 1,r = 0;
for(int i = 1;i<=m;i++)
{
while(l>q[i].l) add(--l);
while(r<q[i].r) add(++r);
while(l<q[i].l) del(l++);
while(r>q[i].r) del(r--);
ans[q[i].id] = res;
}
for(int i = 1;i<=m;i++)
cout<<ans[i]<<'\n';
return 0;
}
当然,上述算法还能优化,比如奇偶排序(优化常数)、二次离线(去掉一只 log)。感兴趣的可以自己学习。
Part.3 带修莫队
普通莫队是不支持修改的,如果有修改操作的话,就可以请出带修莫队了!
先给一道例题:P1903,其实就是在普通莫队的例题基础上加一个单点修改。
其实就是给普通莫队加一个时间戳,即之前有多少个修改操作,排序时以其作为第三关键字。处理答案时就多记一个当前时间戳 \(t\)。每次把 \(t\) 移动到询问的时间戳,进行修改,并把在询问区间内的修改加入贡献。
当 \(B\) 取到 \(n^{\frac{2}{3}}\) 时,有最优复杂度 \(O(n^{\frac{5}{3}})\)。我太弱了,不会证明。
贴上例题代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 133333+5,M = 1e6+5;
int qsize;
struct que{
int id,t,l,r;
inline friend bool operator < (que x,que y)
{
if(x.l/qsize!=y.l/qsize) return x.l/qsize<y.l/qsize;
if(x.r/qsize!=y.r/qsize) return x.r/qsize<y.r/qsize;
return x.t<y.t;
}
}q[N];
struct op{
int p,x;
}o[N];
int n,m,ans,mp[M],a[N],qcnt,ocnt,out[N];
inline void add(int x)
{
mp[x]++;
if(mp[x]==1) ans++;
}
inline void del(int x)
{
mp[x]--;
if(!mp[x]) ans--;
}
signed main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>n>>m;
qsize = pow(n,2.0/3.0);
for(int i = 1;i<=n;i++)
cin>>a[i];
for(int i = 1,x,y;i<=m;i++)
{
char op;
cin>>op>>x>>y;
if(op=='Q') q[++qcnt] = {qcnt,ocnt,min(x,y),max(x,y)};
else o[++ocnt] = {x,y};
}
sort(q+1,q+qcnt+1);
int l = 1,r = 0,las = 0;
for(int i = 1;i<=qcnt;i++)
{
while(r<q[i].r) add(a[++r]);
while(r>q[i].r) del(a[r--]);
while(l>q[i].l) add(a[--l]);
while(l<q[i].l) del(a[l++]);
while(las<q[i].t)
{
las++;
if(o[las].p>=l&&o[las].p<=r) del(a[o[las].p]),add(o[las].x);
swap(a[o[las].p],o[las].x);
}
while(las>q[i].t)
{
if(o[las].p>=l&&o[las].p<=r) del(a[o[las].p]),add(o[las].x);
swap(a[o[las].p],o[las].x);
las--;
}
out[q[i].id] = ans;
}
for(int i = 1;i<=qcnt;i++)
cout<<out[i]<<'\n';
return 0;
}
Part.4 回滚莫队
回滚莫队解决的问题就是加入一个数很好维护,但是删除这个数不好维护(比如区间最值之类的)。其思想就是每次右端点慢慢加,左端点到目标点时计算答案再回到原来的点。
仍然甩出一道例题:SP20644。让你统计区间中和为零的区间最大长度。
先把问题转化成前缀和,相当于在问你区间中前缀和相同的地方最大的长度,然后就变成了P5906。
我们还是按照普通莫队的方式排序。回滚莫队由以下几部分组成:
- 左右端点在一个块内,直接暴力做;
- 左端点的块和上一个的不同,设这个块的右端点为 \(rt\),那么 \(now_l\) 就要移动到 \(rt+1\),\(now_r\) 就要移动到 \(rt\),并把当前答案清零;
- \(now_r\) 移动到当前询问的右端点,一边移动一边计算答案;
- \(now_l\) 移动到当前询问的左端点,注意移动完之后需要回到原来的位置,所以记录原来的答案以便复原,其余的正常计算贡献;
- \(now_l\) 移动回去,我们只需要把这段区间的贡献消掉就行,这是难点。然后把答案还原。
需要注意的是,回滚莫队不支持奇偶排序!
回到这道例题,考虑如何消掉贡献。我们计算答案的时候维护一个 \(mx_i\) 表示 \(i\) 最先出在那个位置,而 \(mx_i\) 小于原来 \(now_i\) 的就会消掉贡献。
放代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 5e4+5;
int n,m,a[N],b[N],blk,lt[N],rt[N];
struct node{
int l,r,id;
inline void init(int x){cin>>l>>r,l--,id = x;}
inline friend bool operator < (node x,node y)
{
if(b[x.l]!=b[y.l]) return x.l<y.l;
return x.r<y.r;
}
}q[N];
int mn[N<<1],mx[N<<1],ans[N];
signed main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>n>>m;
blk = sqrt(n);
a[0] = n,b[0] = 1;
for(int i = 1;i<=n;i++)
cin>>a[i],b[i] = (i-1)/blk+1,a[i]+=a[i-1];
for(int i = 1;i<=b[n];i++)
rt[i] = i*blk;
rt[b[n]] = n;
for(int i = 1;i<=m;i++)
q[i].init(i);
sort(q+1,q+m+1);
int l = 0,r = 0,las = 0,tmp = 0;
for(int i = 1;i<=m;i++)
{
if(b[q[i].l]==b[q[i].r])
{
for(int j = q[i].l;j<=q[i].r;j++)
mx[a[j]] = 0;
tmp = 0;
for(int j = q[i].r;j>=q[i].l;j--)
if(!mx[a[j]]) mx[a[j]] = j;
else tmp = max(tmp,mx[a[j]]-j);
ans[q[i].id] = tmp;
for(int j = q[i].l;j<=q[i].r;j++)
mx[a[j]] = 0;
continue;
}
if(b[q[i].l]!=las)
{
while(l<rt[b[q[i].l]]+1) mx[a[l]] = mn[a[l]] = 0,l++;
while(r>rt[b[q[i].l]]) mx[a[r]] = mn[a[r]] = 0,r--;
r = l-1;
tmp = 0,las = b[q[i].l];
}
while(r<q[i].r)
{
r++;
if(!mn[a[r]]) mn[a[r]] = mx[a[r]] = r;
else tmp = max(tmp,r-mn[a[r]]),mx[a[r]] = r;
}
int _l = l,res = tmp;
while(_l>q[i].l)
{
_l--;
if(!mx[a[_l]]) mx[a[_l]] = _l;
else res = max(res,mx[a[_l]]-_l);
}
ans[q[i].id] = res;
while(_l<l)
{
if(mx[a[_l]]==_l) mx[a[_l]] = 0;
_l++;
}
}
for(int i = 1;i<=m;i++)
cout<<ans[i]<<'\n';
return 0;
}
另外推荐一道回滚莫队好题:AT_joisc2014_c。
Part.5 树上莫队
还是先给一道例题:SP10707。
我们考虑对树进行 DFS,求出其欧拉序。
给个例子:
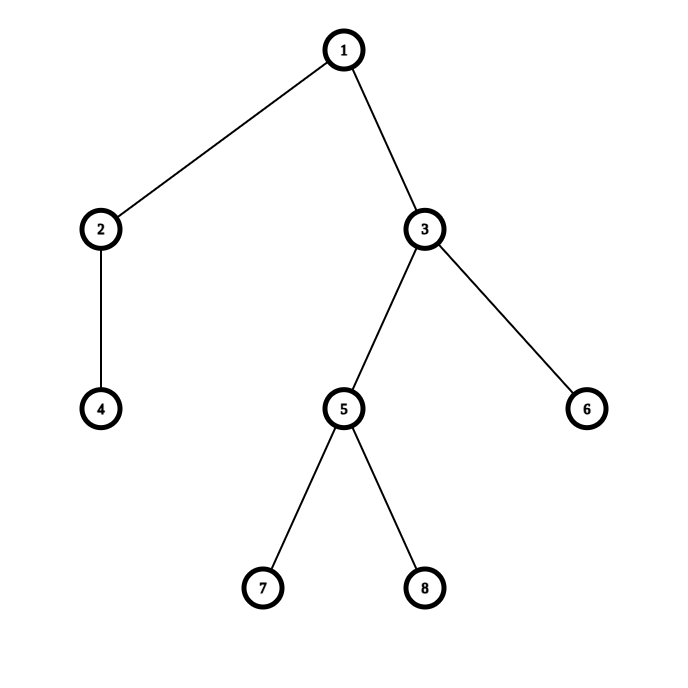
这颗树的欧拉序为 \(1,2,4,4,2,3,5,7,7,8,8,5,6,6,3,1\)。我们记节点 \(i\) 第一次出现的位置为 \(st_i\),第二次出现的位置为 \(ed_i\)。
考虑询问 \(u\) 到 \(v\) 这条路径,不妨设 \(st_u<st_v\),分两种情况讨论:
- \(v\) 在 \(u\) 的子树中,我们只需要去掉 \(v\) 的子树,询问区间就是 \(st_u\sim st_v\);
- 否则,我们需要去掉 \(u,v\) 的子树,那么询问 \(ed_u\sim st_v\) 即可。但是发现走到 \(st_v\) 时还没有退出 \(lca(u,v)\) 的子树,所以还要单独算上 \(lca(u,v)\)。
其他的和普通莫队都是一样的,但注意要开两倍空间!
上代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5+5;
int n,m,idx,ans[N],a[N],b[N],tt,cnt[N],res,st[N],ed[N],pre[N],son[N],dep[N],top[N],sz[N],f[N],qsize;
vector<int> g[N];
bool vis[N];
void dfs1(int u,int fa)
{
f[u] = fa,dep[u] = dep[fa]+1,sz[u] = 1,st[u] = ++idx,pre[idx] = u;
for(auto v:g[u])
{
if(v==fa) continue;
dfs1(v,u);
sz[u]+=sz[v];
if(sz[v]>sz[son[u]]) son[u] = v;
}
ed[u] = ++idx,pre[idx] = u;
}
void dfs2(int u,int tp)
{
top[u] = tp;
if(!son[u]) return;
dfs2(son[u],tp);
for(auto v:g[u])
{
if(v==f[u]||v==son[u]) continue;
dfs2(v,v);
}
}
inline int Lca(int x,int y)
{
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
x = f[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
return x;
}
struct node{
int l,r,lca,id;
inline void init(int x)
{
id = x;
int u,v;
cin>>u>>v;
if(st[u]>st[v]) swap(u,v);
lca = Lca(u,v);
if(lca==u) l = st[u],r = st[v],lca = 0;
else l = ed[u],r = st[v];
}
inline friend bool operator < (node x,node y)
{
if(x.l/qsize==y.l/qsize) return x.r<y.r;
return x.l<y.l;
}
}q[N];
inline void add(int x)
{
cnt[x]++;
if(cnt[x]==1) res++;
}
inline void del(int x)
{
cnt[x]--;
if(cnt[x]==0) res--;
}
inline void work(int x)
{
x = pre[x];
vis[x]^=1;
if(vis[x]) add(a[x]);
else del(a[x]);
}
signed main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>n>>m;
for(int i = 1;i<=n;i++)
cin>>a[i],b[++tt] = a[i];
sort(b+1,b+tt+1),tt = unique(b+1,b+tt+1)-b-1;
for(int i = 1;i<=n;i++)
a[i] = lower_bound(b+1,b+tt+1,a[i])-b;
for(int i = 1,u,v;i<n;i++)
cin>>u>>v,g[u].push_back(v),g[v].push_back(u);
dfs1(1,0),dfs2(1,1);
for(int i = 1;i<=m;i++)
q[i].init(i);
qsize = sqrt(n);
sort(q+1,q+m+1);
int l = 1,r = 0;
for(int i = 1;i<=m;i++)
{
while(l>q[i].l) work(--l);
while(r<q[i].r) work(++r);
while(l<q[i].l) work(l++);
while(r>q[i].r) work(r--);
if(q[i].lca) work(st[q[i].lca]);
ans[q[i].id] = res;
if(q[i].lca) work(st[q[i].lca]);
}
for(int i = 1;i<=m;i++)
cout<<ans[i]<<'\n';
return 0;
}
Part.6 总结
莫队是个非常好的数据结构,建议深度学习!
码字不易,给个赞吧~



评论区