


本书中, eBPF 被称为一种 革命性的 内核技术,被广泛应用于网络、观测 和 安全工具中。
这种技术允许你在不重新编译内核的情况下,使能你的自定义工具,与内核数据进行交互。听起来很厉害。
1.1 追踪溯源,伯克利包过滤器
eBPF 的祖宗就是伯克利包过滤器,英文名:The Berkeley Packet Filter,简称 BPF。Berkeley 是一个实验室,全称为:劳瑞斯·伯克利国家实验室(Lawrence Berkeley National Laboratory )。1993 年,伯克利实验室的两位大哥 Steven McCanne 和 Van Jacobson 联名发表了一篇文章《The BSD Packet Filter: A New Architecture for User-level Packet Capture》 ,BPF 就此问世。
这个 BPF 很纯粹,就是用来决策网络包的接受和拒绝的。若收到的数据包是一个 IP 数据包,返回true(代表接受),否则返回false(代表拒绝)。主要代码就 4 行:
ldh [12]
jeq #ETHERTYPE IP, L1, L2
L1: ret #TRUE
L2: ret #0
这就是 eBPF 程序的一个基本核心思路。
1997 年,当时的 BPF(那时还不叫 eBPF)被引入内核(v2.1.75),成功应用于经典的 tcpdump 工具中。
tcpdump:网络抓包工具,用于捕获和分析网络数据包。
2012年,内核(v3.5)引入了seccomp-bpf,开启了 BPF 程序控制用户空间系统调用的时代(第10 章会详细介绍)。书中评价:”这使得 BPF 从简单的包过滤器向如今强大的通用平台迈出的第一步。“
从这时开始,即使 BPF 依旧被称为 “包过滤器”,似乎就不是很贴切了。但大家都这么叫,whatever!
1.2 从 BPF 到 eBPF
内核(v3.18)版本在2014年,BPF 就被真正革新了。于是开始称其为 eBPF(extended BPF)。BPF 鸟枪换炮,大放异彩。
【表1.2.1:eBPF 鸟枪换炮】
| 对比项 | BPF | eBPF | 指引 |
|---|---|---|---|
| 指令集 | 32bit | 64bit | |
| maps | 这是啥? | 引入了maps,用于内核态和用户态数据交互 |
第 2 章 |
| 系统调用 | 极其有限 | 增加bpf()系统调用,这是真正的绿色通道 |
第 4 章 |
| 辅助函数 | 喵喵喵? | 开发 eBPF 工具的基础轮子 | 第 2/6 章 |
| 验证器 | 需要验证啥? | 只有被验证为安全的 eBPF 程序才能被运行 | 第 6 章 |
1.3 向生产环境继续演化
自 2005 年开始,内核中就引入了一种名为 “探针” 的技术(kprobe)。基于这个技术,你可以将 “探针” 预埋到内核代码的任意指令上。通过编写一个内核模块,控制探针的注册、释放,来调试或监测系统的性能。
探针技术,使 eBPF 的应用登上了一个新的高度。2015 年,kprobe 被加入到 eBPF 中。与此同时,若干个 hook 点被加入到内核网络协议栈中,拓宽了 eBPF 处理网络的能力。
2016 年,Brendan Gregg 大神将 eBPF 运用的炉火纯青,迅速出圈,在基础设施和系统运营领域可谓无人不晓。他曾评价道:“ eBPF 为 Linux 带来了超能力。”
同年,著名的 Cilium 项目问世了。【待补充】
2017 年,另一个名为 Katran 的开源项目(eBPF + XDP,用于负载均衡)被研发,并在脸书(Facebook.com)大规模应用。展示了 eBPF 的极高的上限。
终于,在 2018 年,eBPF 成为 Linux 的一个子系统,维护者为:Daniel Borkmann、Alexei Starovoitov 和后来加入的 Andrii Nakryiko。也是在这一年,BTF (BPF类型格式)这个核心概念被提出,为 eBPF 的可移植性,提供了一种方案。
LSM BPF 在 2020 年被引入内核。从此,BPF 程序可以附加在 LSM(内核安全模块)钩子上,用于安全访问控制了。
总结:经过多年的革新,eBPF 终于有能力站在一个全新的高度,赋予开发者触碰内核指令的超能力。曾经,BPF 程序一度被限制在 4096 条指令内,但如今,eBPF 支持的指令数已经达到 100w,并且支持尾调用和函数调用等特性(见第 2/3 章)。
回首过去,向这一代贡献于 eBPF 事业的开发者们致敬!
1.4 取名困难症
如今,eBPF 的作用已经远超它初创之时的 “包过滤器” 了,再去纠结现在的 eBPF 应该叫什么已经没有意义了。就姑且这样称之,因为取名字实在是太困难了。
- eBPF 交互的系统调用,叫
bpf(); - eBPF 辅助函数开头前缀为
bpf_; - BPF程序类型(你看吧,这里书中又用的 BPF。所以不要纠结加不加 e 了,就是个代号)开头前缀为
BPF_PROG_TYPE;
不过,在内核以外的领域,eBPF 这个名字更普遍一些。
1.5 Linux 内核
若想理解 eBPF ,需要一些简单内核知识的储备。
简单整理一下书中涉及的知识点:
内核是应用程序和硬件的中间层。这是因为应用程序所处的用户空间,不能直接访问硬件。- 内核向用户空间开放
系统调用接口,来执行操作硬件的高级行为。 - 硬件访问包括:读写文件、收发网络包、访问内存等。
- 内核还有一个作用是协作
进程,来支持多个应用程序的同时运行。
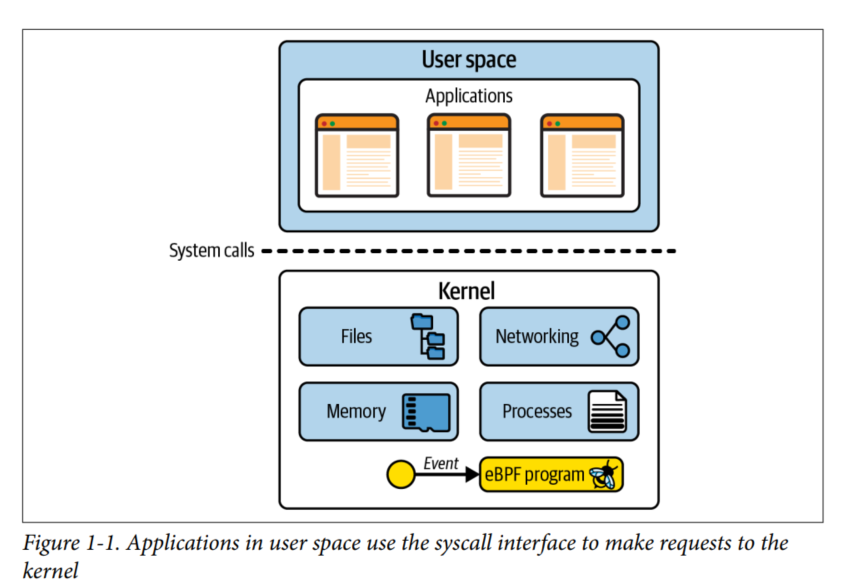
- 开发应用程序时,我们不会直接使用原生的
系统调用,而是使用对应高级语言提供的标准库。 - 可以使用
strace工具来观测内核系统调用。
应用程序的运行是极其依赖系统调用的。因此,如果我们对系统调用理解很深,那么我们就会对应用程序的运行过程能够具有非常清晰的把握。
但是,但是但是,如何观测一个系统调用呢?举一个例子:如果我想拦截打开文件的系统调用,从而能够搞清楚一个应用程序运行时访问了哪些文件,我要怎么做?简单地找到内核系统调用对应的函数入口,然后增加打印输出吗???
1.6 为内核增加新功能
内核是极其庞大且复杂的。以内核 5.12 版本来说,就已经容纳大约 28,800,000 行代码了。因此如果想为内核增加一个功能,需要你十分百分千分万分了解内核源码。(如果你是内核的开发者,当我没说)
此外,如果你想把你对内核的修改提交到内核上游主线中,那么你的面前,将是一座比技术还高的山。Linux 是时下最流行的操作系统,它跑在全球数以亿计的机器之上,其对稳定性的要求可想而知!Linux 是有圈子,有社区的。而你写的代码,在保证稳定性的同时,需要兼具社区内大佬们的认可(想象一下 Linus 和一众大佬默默的注视),让他们认为你的代码值得合入到 Linux 最新的发行版中。2013 年的一篇文章《Will My Patch Make It? And How Fast? 》中给出了结论 —— 你的 patch 被接纳的概率,仅有 1/3。
退一万步讲,现在你已经实现了一个绝妙的方式来拦截文件读取的系统调用,社区里的大佬们也都十分青睐你这份提交。那么需要多久用户才能使用到你的代码呢?
三个月?半年?一年?两三年?或是永远都用不上?
且看当前 kernel 最新发行版的版本:v6.7(截止 2024/01/08),而当前 REDL 8.8(红帽8.8,2023/05发布)依旧使用 4.18 版本的内核。
追求稳定,才是企业应用机的首要需求。
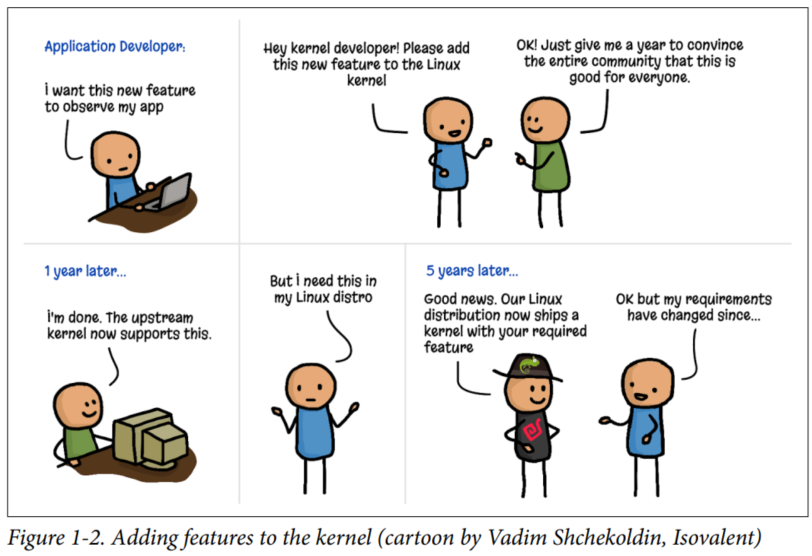
书里给出了一个段子——向内核中添加一个新特性,如下图。
1.7 内核模块
为了避免修改一个内核功能就要等待好几年,你可以通过另一种技术暂时实现这个功能。
这种技术就是内核模块。
你可以写一个内核模块,通过动态加载和卸载的方式,抓取当前进程(是的,应用程序运行起来就是进程了)打开的文件列表。这就又回到了我们最初提出的问题 —— 你需要对内核流程和内核结构体十分百分千分熟悉。否则,当你写的这个东西若是有 bug,一旦被加载到内核,就会引起系统崩溃。
为了增加一个功能把系统搞崩了,不值得。
安全运行,不仅仅要求不崩溃,而且要求你写的东西没有漏洞,不会被黑客抓到攻击的机会。
重头戏来了——
eBPF 提供了一种与众不同的安全校验方法,那就是 eBPF Verifier(又叫 eBPF 验证器)。这个验证器用于 eBPF 程序运行前的安全验证,避免空指针、死循环等不安全情况的出现。
1.8 eBPF 程序的动态加载
eBPF 最大的特点就是动态加载。当你把一个 eBPF 程序加载到内核中时,它会立刻生效;当你终止其运行时,它的检测功能也会立刻终止。就是这样可动态热插拔的效果,叹为观止。你甚至都不需要重启机器。
例如,你写了一个 eBPF 程序来监控打开文件。当你把它载入内核,它会一直潜伏在那里,——尽管当前没有打开的文件(只是举例,因为打开文件操作太常见了),而一旦有文件打开事件触发,它马上会按照你设定的逻辑开始工作。这种超级能力,你可以立刻知晓当前机器上这一个事件点发生的所有前因后果。有了 eBPF,你就有了上帝之手。
书中给出了另一张图,使用 eBPF 后,段子变了。

1.9 eBPF 程序之高性能
eBPF 不需要用户态和内核态之间的切换,这是它高性能的原因之一。
一段 eBPF 一旦被加载和编译(编译器被称为 JIT,第 3 章会讲),它就同本地机器指令一般在 CPU 上运行。
2018 年的一篇论文《The eXpress data path: fast programmable packet pro‐cessing in the operating system kernel》提到,通过 XDP(eXpress Data Path,快速数据路径,一种用于网络 eBPF 编程的 Hook 点) 实现路由转发比常规的内核实现提升 2.5 倍的性能;而基于 XDP 的负载均衡相较于 IPVS 的性能提升为 4.3 倍。
对于 eBPF 在性能跟踪和观测中的应用来说,其一个突出的优势在于,被观测的事件和数据可以直接在内核中过滤,并仅选择有价值的信息传递给用户空间。在某种程度上,资源利用率也得到了提升。
1.10 eBPF 与云原生
如今依旧火热的云原生中也有 eBPF 的一席之地。
在云原生环境下,用户更倾向于将应用服务部署在容器中,裸机应用变得很少了。当然,容器部署和裸机部署归根结底都是为了应用程序更好的运行。这些程序共享同一个机器的硬件资源和内核,因此 eBPF 是用来集中观测它们性能表现和负载的最好手段。如图所示:
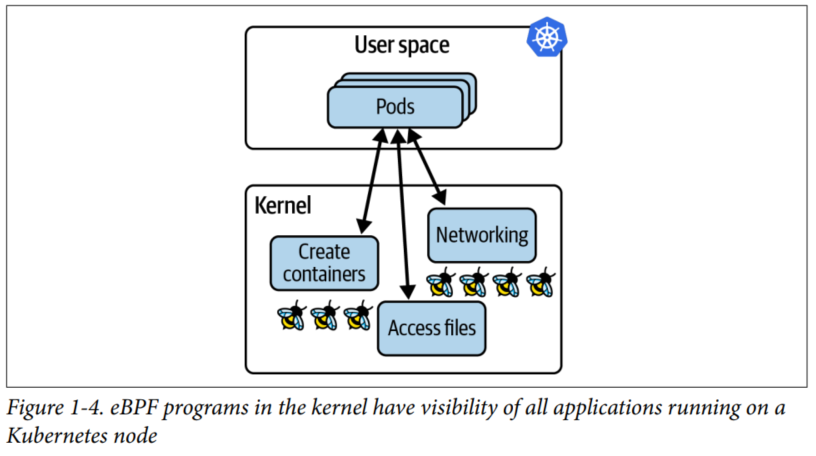
对于容器部署来说,能够集中观测所有容器,同时兼备动态加载。基于这两点,eBPF 也成为云原生的超能力,实至名归。
接下来是与 sidecar 模型的对比。
书里在这部分并没有对 sidecar给出一个较清晰的解释,我这里简单扩展一下。(以下内容摘录自知乎回答 Sidecar 架构模式 - 知乎 (zhihu.com))
sidecar,直译为侧车,如图:

类似于小鬼子摩托车,sidecar 模式就是指在原来的业务逻辑上再新加一个抽象层。这种模式很好的印证了那个计算机的名言:
“计算机科学领域的任何问题都可以通过增加一个简介的中间层来解决。”
“Any problem in computer science can be solved by another layer of indirection.”
sidecar 模式在不改变主应用的情况下,会起来一个辅助应用,来辅助主应用做一些基础性的甚至是额外的工作。这个辅助应用不一定属于应用程序的一部分,而只是与应用相连接。这就像是挎斗摩托车,每个摩托车都有自己独立的辅助部分,它随着主应用启动或停止。因为 sidecar 其实是一个独立的服务,我们可以在上面做很多东西,例如 sidecar 之间相互通信、或者通过统一的节点控制 sidecar ,从而达到 Service Mesh。

现在我们回到书中内容。这种 sidecar模式主要应用于向 k8s 容器中的应用添加日志、记录、跟踪、安全性等功能。
我们暂时忽略原理。这种 sidecar 模式有以下几个缺点:
- 应用程序的
pod必须重启才能添加sidecar。 - 必须修改应用程序的
yaml文件。 - 若一个
pod包含多个容器,这些容器的就绪时间不可预测。 - 由于
sidecar作用在应用层,所以一些网络应用在收发网络包时必须通过完整的内核协议栈,效率大大降低。以Service mesh proxy(基于sidecar实现的服务窗格应用)为例,下图解释了这个场景:
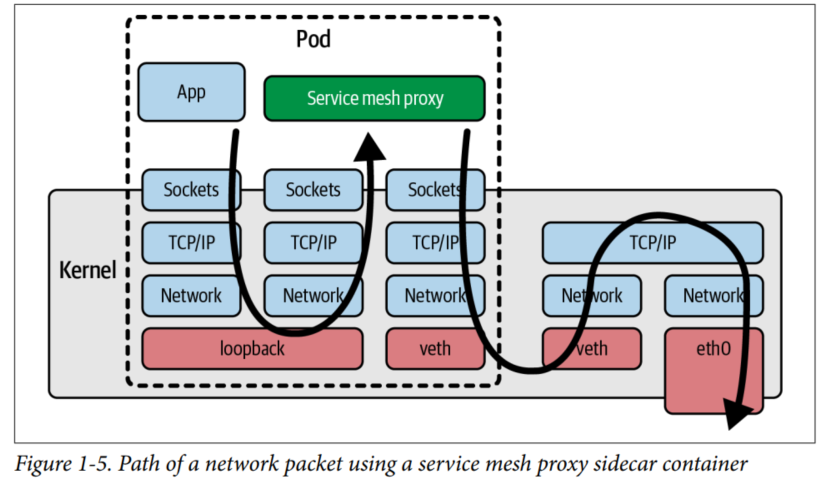
自然,eBPF 可以很好的解决这些问题。
- eBPF 无需重启即可生效。
- eBPF 对用户程序无侵入性。
- eBPF 是及时的,性能很高。
- eBPF 作用于内核态,不用走内核协议栈。
另外,由于 eBPF 洞察一切,合理应用,一些黑客程序也就无所遁形了。我们将在第 8 章详细讨论安全守护主动丢弃网络包的能力。
1.11 小结
这一章主要从概念上介绍了 eBPF 这种内核超能力。它给了我们一种新的方式去改变内核的行为、追踪内核的动作、监视应用的运行。它支持动态加载,立即生效,对系统和应用的侵入很小。
下一章,我们将深入细节,通过一个 eBPF 程序,来了解它的组成。且听下回分解。



评论区