


C++虚继承原理与类布局分析
引言
在开始深入了解虚继承之前,我们先要明白C++引入虚继承的目的。C++有别于其他OOP语言最明显的特性就是类的多继承,而菱形继承结构则是多继承中最令人头疼的情况。
我们都知道,当派生类继承基类时,派生类内部会保存一份基类数据的副本。在D->B|C, B|C->A的菱形继承结构中,B、C各自存有一份A成员变量的副本,这导致D继承B、C后同时保存了两份A成员变量,这就导致了空间浪费和语法二义性的问题。
所以C++引入了虚继承,用于解决菱形继承导致的数据冗余。
本文的目标是探究虚继承的实现方式和类布局(Class Layout)的具体规则,主要内容源自于本人对C++: Under the Hood的解读和提炼。
不过在开始之前,我们需要先熟悉一下普通继承下的类布局,方便与之后的虚继承进行对比。
请注意,以下用于分析的数据皆来自于MSVC的编译结果。C++标准定义了一些基本规范,但不同编译器的实现方式可能会有所差异,所以内容仅具有一定的参考性。
单继承
以下是由A类派生B类的单继承例子:
class A
{
public:
int a1;
int a2;
};
class B : public A
{
public:
int b1;
int b2;
};
通过在VS中启用Class Layout的输出,我们可以得到以下内容:
class A size(8):
+---
0 | a1
4 | a2
+---
class B size(16):
+---
0 | +--- (base class A)
0 | | a1
4 | | a2
| +---
8 | b1
12 | b2
+---
Visual Studio中查看类布局的方法可以参考这篇博客。
看起来可能有点抽象,它其实是等价于下图中的内容:
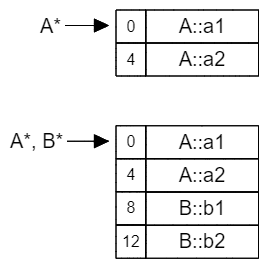
由于派生类继承了其基类的所有属性和行为,因此派生类的每个实例都将包含基类实例数据的完整副本。在B中,A的成员数据摆放在B的成员数据之前。虽然标准并没有如此规定,但是当我们需要将B类的地址嵌入A类的指针时(例如:A *p = new B();),这种布局不需要再添加额外的位移,就可以使指针指向A数据段的开头(在接下来的多继承中更能体现这么做的好处)。图中A*、B*指针指向的位置也体现了这一点。
因此,在单继承的类层次结构中,每个派生类中引入的新实例数据只是简单地附加到基类的布局末尾。
多继承
class A
{
public:
int a1;
int a2;
};
class B
{
public:
int b1;
int b2;
};
class C : public A, public B
{
public:
int c1;
int c2;
};
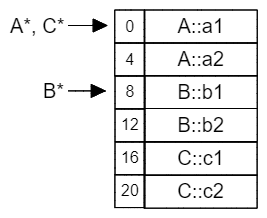
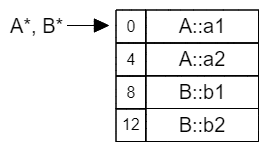
类C多重继承自A和B,与单继承一样,C包含每个基类实例数据的副本,并且置于类的最前方。与单继承不同是,多继承不可能使每个基类数据的起始地址都位于派生类的开头。从图中也可以看出,在基类A占据起始位置后,基类B只能保存在偏移量为8的位置。这就使得将C*转换为A*和B*时的操作出现了差异。
C c;
(void *)(A *)&c == (void *)&c
(void *)(B *)&c > (void *)&c
(void *)(B *)&c == (void*)(sizeof (A) + (char *)&c)
这几个判断语句的结果都为true,因此可以看出当C*转为B*时,会在原地址的基础上进行偏移。这也是多继承带来的开销之一。
编译器实现可以采用任何顺序布置基类实例和派生类实例数据。MSVC通常的做法是先按声明顺序布局基类实例,然后按声明顺序布置派生类的新数据成员。 不过在后续的例子中我们将会看到,当部分基类具有虚基类表(或虚函数表)而其他基类没有时,情况就不一定如此了。
菱形继承
现在就搬出我们在文章开头提到的菱形继承的例子,来看看具体的布局是怎么样的。
class A
{
public:
int a1;
int a2;
};
class B : public A
{
public:
int b1;
int b2;
};
class C : public A
{
public:
int c1;
int c2;
};
class D : public B, public C
{
public:
int d1;
int d2;
};
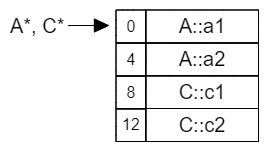
类B和C都继承了A,因此也都保存了一份基类A的实例数据副本。
当类D同时继承了类B和C之后,也完整地保存了B和C的实例数据副本,也就导致D中出现了两份A的实例数据副本。
编译器不能确定我们究竟是要访问从B继承来的A成员,还是从C继承来的A成员,从D*转换到A*的偏移量也无法确定。因此,下面这些操作都是具有二义性的,不能成功编译:
D d;
d.a1 = 1; // E0266 "D::a1" 不明确
A *p_a = (A *)&d; // C2594 “类型强制转换”: 从“D *”到“A *”的转换不明确
想要成功执行的话,就必须显式地声明访问路径,以消除二义性:
D d;
d.B::a1 = 1; // 或者d.C::a1
A *p_a = (A *)(B *)&d; // 或者(A *)(C *)&d
虚继承
为了解决这一问题,C++引入了虚继承的概念。在仅保留一份重复的实例数据副本的情况下,通过虚基类表(vbtable)来访问共享的实例数据。听起来有些难以理解,所以接下来我会通过分析虚继承下的类布局来解释虚继承语法的实现。
我们先来分析单继承情况下,虚继承与普通继承之间的类布局差异。
class A
{
public:
int a1;
int a2;
};
class B : public A
{
public:
int b1;
int b2;
};
class C : virtual public A
{
public:
int c1;
int c2;
};
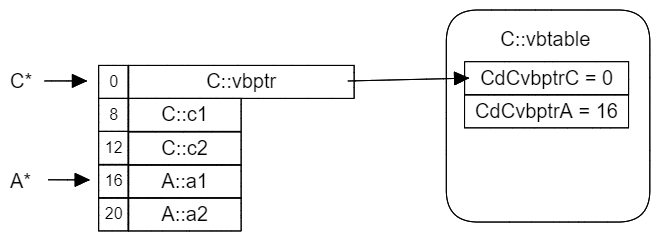
A为基类,B继承于A,C虚继承于A。
通过对比B和C的类布局我们可以发现两个明显的差异:
- 虚继承中,派生类布局的起始位置增加了
vbptr指针,该指针指向vbtable - 虚继承中,基类的实例数据副本被放置在了派生类的末尾
而vbtable中的两个条目也很好理解,我们首先要知道XdYvbptrZ表示的是在X类中,Y的vbptr到Z类入口的偏移量。因此:
- 第一条记录
CdCvbptrC = 0表示,C类中,C的vbptr到C类入口的偏移量为0。 - 第二条记录
CdCvbptrA = 16表示,C类中,C的vbptr到A类入口的偏移量为16。从图中也可以看出C类中,C::vbptr的保存位置为0,A类的入口位于16,因此偏移量为16。
在数据访问的过程中,需要用到vbtable中的偏移量来计算访问地址,这就涉及到了查表+偏移的操作。因此,虚继承的访问开销会比前面在多继承中提到的固定偏移计算来得更大,与此同时vbptr和vbtable也造成了额外的内存开销。
从单继承的例子来看,虚继承带来了更大的时间和内存开销,但却没有体现出任何的额外优势。并且也看不出vbptr和vbtable存在的必要性,毕竟为什么我们不直接让A* = C* + 16呢?
而接下来通过菱形继承的例子,我们就会明白这种做法的必要性。
虚继承——菱形继承
class A
{
public:
int a1;
int a2;
};
class B : virtual public A
{
public:
int b1;
int b2;
};
class C : virtual public A
{
public:
int c1;
int c2;
};
class D : public B, public C
{
public:
int d1;
int d2;
};
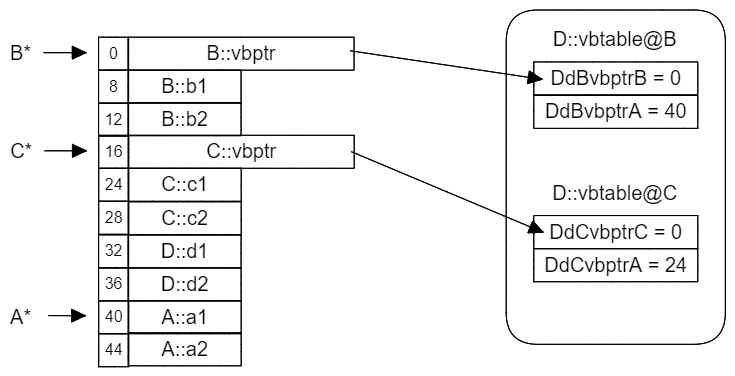
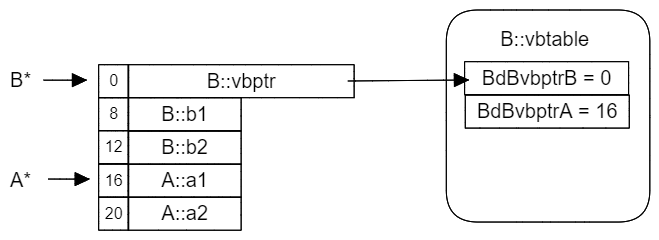
需要注意,在这个例子中B和C虚继承于A,而D则是普通继承于B和C。
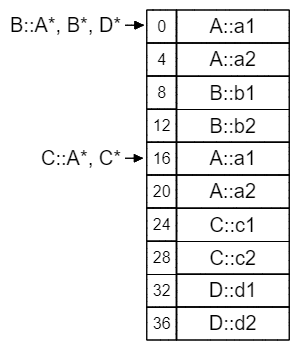
在为菱形继承添加上虚继承之后,我们可以明确地看到B和C结尾的A实例数据副本,在D的结尾被合并成了一份。与此同时,编译器根据D的布局结构创建了新的vbtable,B和C的vbptr也被修改为指向新的vbtable。
现在我们就可以解答前面提出的问题:“为什么不直接让`A* = C* + 16呢?”
从图中就可以看出,在C类的布局中,C* + 16 == A*是成立的,因此以下代码的运行结果是1
C* p_c = new C();
A* p_a = p_c; // 编译器自动转换的结果
printf("%d", (void*)p_a == (void*)(16 + (char*)p_c)); // 返回1
而在D类之中,C* + 16访问的就是D::d1的地址了,这种做法明显是错误的,因此代码的运行结果是0
C* p_c = new D(); // 注意:这里的C*来源于类型D
A* p_a = p_c;
printf("%d", (void*)p_a == (void*)(16 + (char*)p_c)); // 返回0
所以根本的问题在于,不同类中的A*相对于C*的位置是不固定的,在运行时多态的情况下,我们无法仅在编译阶段计算出确定的偏移量。
但有了vbptr和vbtable之后,无论是C类的C*还是D类的C*,我们都可以访问当前vbptr所指向的vbtable获取偏移量。而vbptr和vbtable都是可以在编译时根据类布局来确定的。所以下面的代码中,无论C*的来源是C类还是D类,运行的结果始终为1
C* p_c = new D();
A* p_a = p_c;
int* vbptr_c = *(int**)p_c; // 这里根据C类的布局知道vbptr位于C*的起始位置(编译时确定)
printf("%d", (void*)p_a == (void*)(*(vbptr_c + 1) + (char*)p_c)); // vbptr_c + 1是因为A*偏移量位于vbtable[1](编译时确定)
虚表指针(vbptr)的位置
关于虚继承的实现方式已经解释的差不多了,接下来我们再介绍几种类布局的情况,以帮助你更好地理解这些概念。
让我们先复习一下上一个章节中的例子来说明:
class A
{
public:
int a1;
int a2;
};
class C : virtual public A
{
public:
int c1;
int c2;
};
我们已经介绍过了这个布局,C虚继承A后,在起始位置添加了vbptr,并将A的实例数据副本布置在了末尾。
让我们把情况弄得稍微复杂一些:
class A
{
public:
int a1;
int a2;
};
class B // 注意,这次B没有继承A
{
public:
int b1;
int b2;
};
class C : virtual public A, public B
{
public:
int c1;
int c2;
};
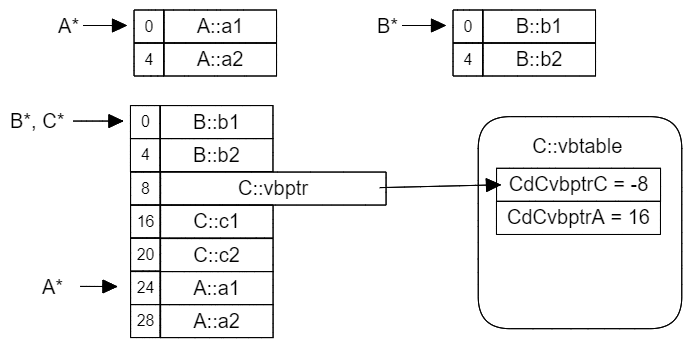
我们让C虚继承A的同时,再普通继承B。这次C发生了两个变化:
vbptr的位置从0变为了8,也就是说vbptr的行为似乎和普通成员变量一样,被布置在基类的成员之后。注意我这里说的是"似乎",因为下一章节我们就会找到特例。- 第二个变化则是
vbtable中的CdCvbptrC的值从0变为了-8,这其实就是受到vbptr位置变化的影响。
共用虚基类表(vbtable)
介绍完“正常情况”后,我们再来看一个特殊情况。
class A
{
public:
int a1;
int a2;
};
class B : virtual public A
{
public:
int b1;
int b2;
};
class C : virtual public A, public B
{
public:
int c1;
int c2;
};
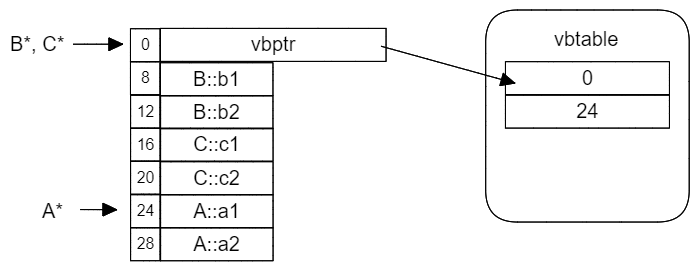
这次我们让B虚继承于A,然后和上一章一样,让C虚继承A的同时,再普通继承B。
可以看到,由于B和C都有vbptr,并且具有公共的虚基类A,导致二者的vbptr合并到了起始位置,并且共用一个vbtable。
后续我经过几次测试后发现一个规律,当派生类同时进行虚继承和非虚继承的情况下,只要非虚继承的基类中存在vbptr指针,那么派生类的虚继承就会与之共用一个vbptr和vbtable。
参考资料
C++: Under the Hood
How virtual inheritance is implemented in memory by c++ compiler?
深入理解C++ 虚函数表
本文发布于2024年4月2日
最后编辑于2024年4月2日



评论区