


视觉slam十四讲 ---CH5 相机与图像
视觉slam中,作为主要传感器的相机自然起到着重要的作用,而相机拍摄的图像及其处理也是我们要做的工作之一。
1. 相机模型
单目相机的针孔模型

上图中的模型即为常见的单目相机的针孔模型示意。
从5-1的左边我们可以看到有很多坐标系交杂在一起。其中以相机光心O为原点所成的右手系为相机坐标系,而物理成像平面上x,y轴以及原点与相机坐标系所平行的坐标系为成像坐标系,而实际上拍摄的图片一般会量化为像素单位,因此一般在图像的左上角设置一个像素坐标系。接下来我们就来研究这如何将一个三维世界下的点转换为像素坐标系下的点。
对于相机坐标系如图所示,是一个Z轴向前的右手坐标系。其中有一些相机本身的参数。
- 镜头的成像中心叫做光心
- 镜头到成像平面的距离叫做焦距f
- 约定相机坐标系下的坐标下标为C
- 约定世界坐标系下的坐标下标为W
对于三维空间上的一个点P从相机到成像平面的轨迹沿Z-Y轴所成平面剖开,所见即为5-1右图。显然两个三角形为相似关系。在注意成像平面成倒像的前提下,不妨有以下推导。
同理对于Z-X轴剖面进行同样的相似三角形分析,有
即
考虑相机会自动纠正倒像为正像,不妨认为小孔模型直接成正像。因此有
这样我们就完成了相机坐标系到成像坐标系的转换。再来考虑成像坐标系到像素坐标系。
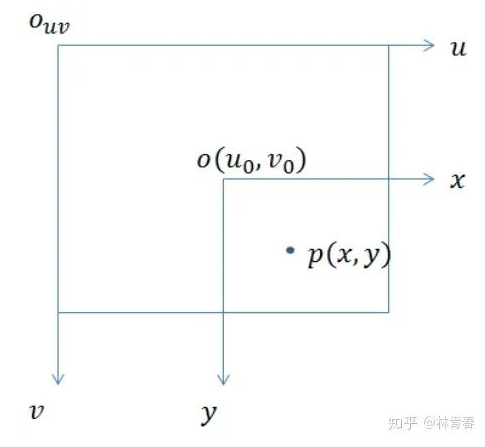
上图是成像坐标系与像素坐标系的关系示意图。其中u,v轴相当于像素坐标下的x,y轴。不难看出,从成像平面坐标到像素坐标我们只需要让成像平面上的点进行伸缩变换以及原点的平移即可。不过注意成像平面的点坐标单位为mm,但是像素坐标的基本单位为单个的像素点。因此还要进行单位的量化。
假设对X,Y的缩放以及量化操作为\(\alpha\)和\(\beta\),像素坐标的平移量分别记为\(c_x\)和\(c_y\),有
带入上述相机坐标到成像平面坐标的转换关系,消掉X'与Y‘有
这样我们就得出了由相机坐标到像素坐标的转换公式。不妨做一些齐次化处理,将上述两个式子写为矩阵相乘的形式。
即
上式中,我们称矩阵K为相机的 内参矩阵,这个参数在相机生产出之后即视为固定不变的参数,一般可以直接获得或者通过对相机进行标定来获得。
在上式中可以看到对于相机坐标系下的坐标,前面都会乘以一个\(\frac{1}{Z}\),其最终的坐标为\((X_C/Z,Y_C/Z,1)\),可以看出这些点都汇聚在\(Z=1\)这个平面上,丢失了Z轴的信息。我们将这个平面称作归一化平面。处理所有的相机坐标系下的点都可以先转换到归一化平面上去处理。
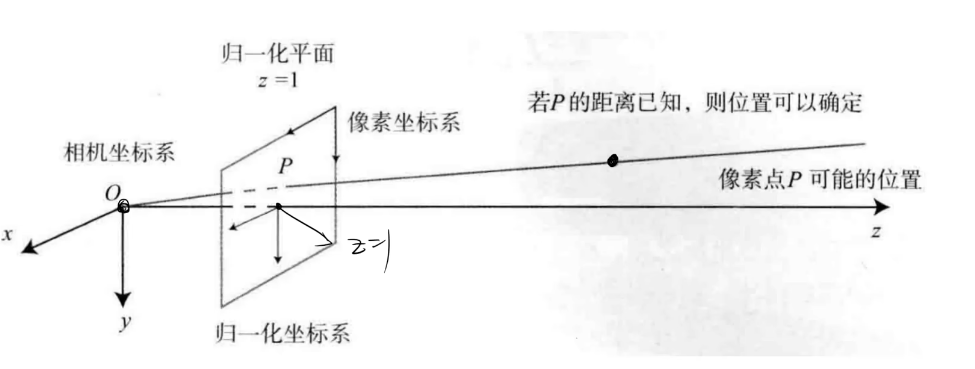
我们一般知道的是物体的世界坐标系,因此在转换之前还要将世界坐标系转换为相机坐标系下的坐标才可。这就是两个三维坐标系的转换,由第三章的知识可知只需要让世界坐标系下的坐标左乘一个变换矩阵或者左乘旋转矩阵然后加上一个平移向量即可。
总结一下
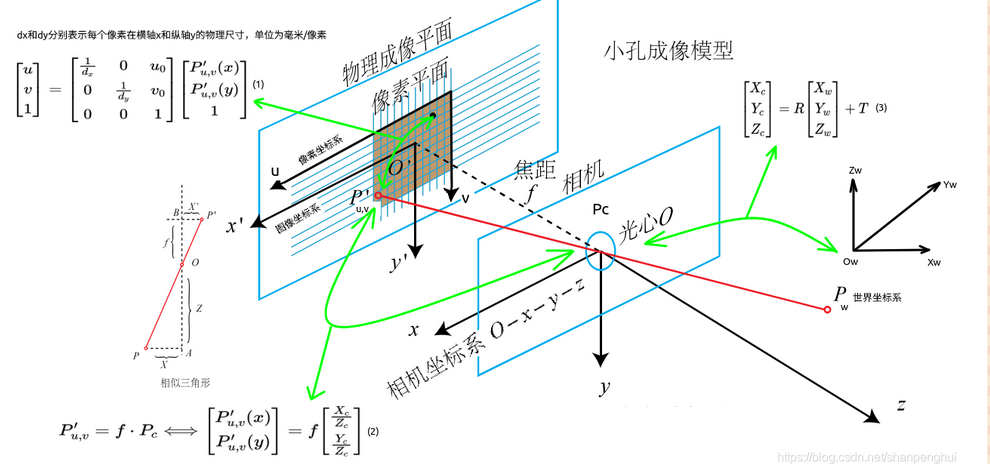
- 对于世界坐标下的点\(P_W\),根据三维刚体运动知识,左乘变换矩阵\(T_{CW}\)将其变换到相机坐标系下的点\(P_C\)。
- 接着将相机坐标系下的点投影到归一化平面上,其坐标也变为\((X_C/Z,Y_C/Z,1)\)
- 然后经过对其归一化坐标左乘相机的内参矩阵,即应用公式\(P_{uv} = \frac{1}{Z}KP\),将归一化坐标转化为像素坐标下的像素坐标。
PS:若有畸变,畸变修正的操作对第二步中的归一化坐标进行处理。
相机图像的畸变
由于各种各样的原因,相机拍摄出的图像相较于本身会有一定的畸变,也就是会变形。常见的畸变类型有径向畸变与切向畸变这两种。
下图是径向畸变的两种表现
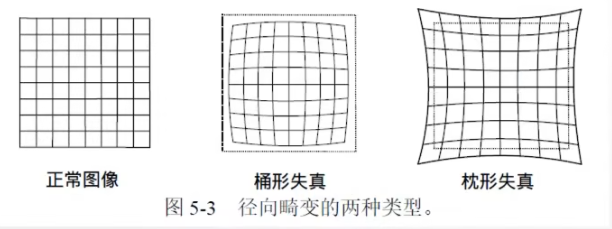

径向畸变一般是由于相机的透镜边缘弯曲形变导致光线聚焦的弯曲,因此一般图像越边缘的地方径向畸变越严重,类似膨胀拉长的感觉。一些全景相机以及鱼眼相机在能看得更广的同时,也伴随着非常严重明显的径向畸变。
对于径向畸变我们可以使用如下的多项式来描述这个畸变。多项式的项数越多,描述程度越精细,计算起来也就越复杂。
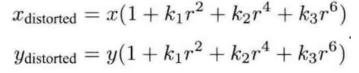
其中\(x_{distorted}\quad y_{distorted}\)为修正后的坐标,\(r = \sqrt{x^2 + y^2}\)。值得注意的是,修正这一操作发生在归一化平面向成像平面的转换这一步。也就是说这里的x,y代表的是归一化后的坐标,即\(x = X_C/Z_C \quad y = Y_C/Z_C\)。其中\(k_1,k_2....\)是多项式的系数,决定着畸变的程度,也是描述畸变的参数。
对于切向畸变,一般是由于相机内部的感光元件传感器安装的并非垂直,导致成像平面不垂直,从而导致切向畸变。
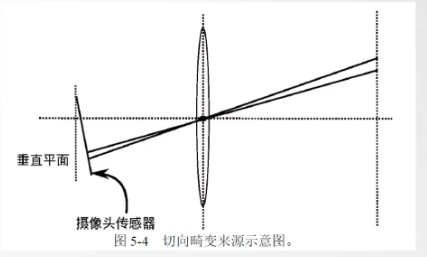
对于切向畸变,可以使用以下多项式模型对其进行描述
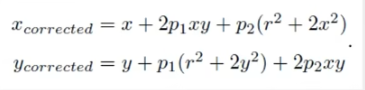
其中的\(p_1,p_2\)也为系数,\(x,y,r\)的定义与径向畸变相同。
可以将径向畸变与切向畸变合并在一起,变成如下对畸变的综合描述。
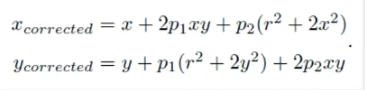
同理这也是在归一化坐标下进行修正。当我们获得像素坐标时,想对其进行畸变修正,首先要由\(u = f_x\frac{X}{Z} + c_x\)求出归一化坐标\(\frac{X}{Z}\),简单的移项运算即可,然后根据上面的公式进行畸变的修正。
双目相机测距模型

由上面可以知道对于单目相机所成的像丢失了深度信息,因此无法根据一张图像判断图像中物体的深度(即远近或者Z轴的坐标)。使用双目相机可以解决这个问题。上图就是双目相机模型。
一些参数:两个相机光心之间的距离叫做基线(base),依旧以相机光心到成像平面的距离为焦距f。上图中的几何模型是成像图的Z-X平面。测距的原理依旧是三角形相似。
设同一物体在两个成像平面所成像的距离为\(l\),也就是图中\(P_l\)与\(P_r\)之间的距离,Z为\(P\)点距离基线终点的三维深度。有如下推导。
经过以上的式子就可以求出P点的深度。其中d称为视差。可以看出视差越大距离越近,视差越小距离越远。就像人眼一样,看太阳的视差小(左右眼看位置相差不大),看近在眼前的物体视差大(左右眼位置差距大)。而基线越大的相机所能支持的精度与所能测到的有效距离就更高。因为大的基线会使得视差的波动误差变得相对不明显。
双目相机看似可以使用一个很简单的公式来求出图像的深度的信息,但是如何确定两个像素与一个物体的匹配是比较困难的,对每一个像素的匹配加计算的计算量也是相当大的。
RGBD相机以及ToF相机
这部分我暂时用不到,就先放在这吧。
图像
在相机采集完后会生成图像,这些图像使用一定的格式存储。
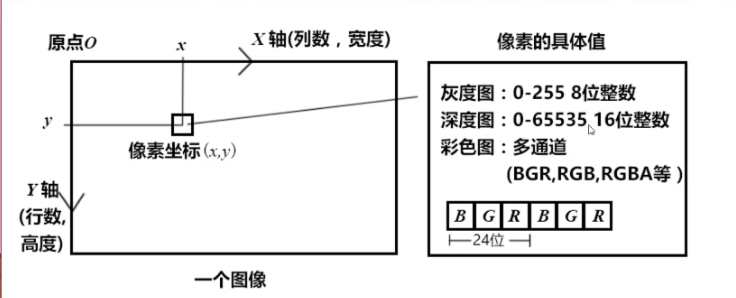
对于一个图像,可以有很多类型。但是大多都是使用矩阵的形式来存储每个像素点,在变成语言中常用类数组矩阵或者列表矩阵的连续数据结构来存储同样连续且分立的像素。
- 二值化图像,也就是黑白图像,取值只有01二值,该点像素取0为黑色,取1为白色,只有一个色彩通道。
- 灰度图,相较于黑白图的01,黑到白之间多了255个过度色,也就是每个像素的可能取值为0-255,正好可由一个8位无符号字符变量(unsigned char)来存储。同样只有一个色彩通道。
- RGB彩色图,有三个色彩通道,分别对应R(red),G(green),B(blue)三种颜色的程度,这三种颜色由各有0-255的程度值,因此一个24位RGB图像需要3个8位无符号字符来存储。在不同的软件中RGB的排列顺序可能是不同的,如OpenCV默认的色彩通道排序是BGR。
对于图片来说,它的像素坐标系与前文中讲到的像素坐标系是一样的,u轴是横向的x轴,代表着有多少列(cols), v轴是竖向的y轴,代表着有多少行(rows)。
因此比较反直觉的是对于给出的一个像素坐标\((x,y)\),代表着这个像素位于第y行第x列,而非大多数程序语言中的先行后列。
这里特别说明一下,对于OpenCV中,Mat类的at接口可以用来访问图像中的像素点。但是其传入的参数
img.at<Vec3b>(i,j),中的i和j却直接表示的是第i行第j列,而非使用像素坐标来定义。而其他的类如Point类或者Rect类之类的点定义都是严格按照上述像素坐标来进行定义的。、
使用OpenCV读取和操作图像
在opencv中,用于存储和操作图像的类名称为Mat(Matrix),给出
一些主要成员。
class CV_EXPORTS Mat
{
public:
// ... a lot of methods ...
...
//! the number of rows and columns or (-1, -1) when the array has more than 2 dimensions
int rows, cols;
//! pointer to the data
uchar* data;
// other members
...
};
可以看出,Mat类存储了图像的行数以及列数,同时使用一个指针指向存储像素的二维矩阵的开头。想要访问图像的像素,可以有如下方式。
Mat img = imread(“/图像位置”);
img.at<Vec3b>(i,j)[0]; //访问B通道的第i行第j列的像素
uchar *row = img.ptr<uchar>(y); //获取第y行的行头指针
for(int i = 0 ; i < img.rows ; i++)
{
row = img.ptr<uchar>(i);
for(int j = 0 ; j < img.cols ; j++)
{
cout << *(row + j) << ' ';
}
cout << '\n';
}
opencv中的Mat互相赋值并不没有重载等号运算符为进行拷贝,因此会出现以下情况
Mat img = imread(/road);
Mat copy = img; //引用性质,两个对象的data指针指向同一片区域
img.at<Vec3b>(20,20)[0] = 251;//修改img同时也会修改copy
想要完全实现复制赋值,可以使用Mat的clone接口或者copyto接口
Mat copy = img.clone();
img.copyto(copy);
区别就是clone会不由分说直接给copy重新分配一块内存,而copyto会看原矩阵的行列与现矩阵是否吻合,若吻合就直接用,不会新分配。
先写到这吧。



评论区