


C/C++内存对齐
what && why
当用户自定义类型时(struct 或 class),编译器会自动计算该类型占用的字节数。
C/C++ 为什么要内存对齐?我道行太浅,摘抄了网上的一个解释。
为了方便从内存中读取数据。假设没有内存对齐,在内存中存储一个 int 变量 x(占 4 字节),放在了地址 2-5 上。现在要读取 x 到寄存器中,CPU 知道读 int 一次应该读 4 字节,但是不会直接读地址 2-5(为什么不会?我也不知道啊!但是 CPU 有直接读 2-5 地址的功能,但它没有用起来),一次读出来,而是先读 0-3,再读 4-7,丢掉多余的字节。可以看到对齐后少读了一次内存,性能肯定得到提升了(我们知道 C/C++ 是追求极致性能的)。
举例
#include <iostream>
using namespace std;
// #pragma pack (1)
struct Test
{
int i1;
char c;
int i2;
double d;
};
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl; // 24
return 0;
}
如果没有内存对齐,Test 类型的大小应该是 4+1+4+8 = 17 字节,经过对齐后变成了 24 字节。
第 5 行注释就是设置内存对齐基数,取值一般是 1, 2, 4, 8,若该值为 1 则表示不对齐(不信就去掉注释再运行一次,输出肯定是 17)。
内存对齐原则
- 整体对齐基数 n:假设默认或通过
#pragma pack ()设置的对齐基数是 i(现在机器一般都是 8,旧一些的应该是 4),struct 中“最大”成员所占用的字节数 j,则n = min(i, j),也就是说这个 struct 类型最终的大小必须是 n 的倍数。 - 成员对齐基数 k:它的计算方式是
k = min(sizeof(memberType), n),它要求每个成员的 offset 必须是 k 的倍数,第一个成员的 offset 为 0。比如一个 short 成员的k = min(sizeof(short), n)
可以看出,当 i = 1 时就是不对齐;当 i >= j 时,i 不起作用。
操练一下
假设 n = 8
先进行成员对齐:
#include <iostream>
using namespace std;
struct Test
{
int i1; // offset为0, 占用第0-3字节
char c; // 1 < 8, offset是1的倍数, 因此offset为4, 占用第4字节
int i2; // 4 < 8, offset是4的倍数, 因此offset为8, 占用第8-11字节
double d; // 8 == 8, offset是8的倍数, 因此offset为16, 占用第16-23字节
// 构造函数
Test(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
// 来验证一下
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl;
Test *pt = new Test(1, 'a', 2, 1.25); // 基地址
unsigned char* ppt = (unsigned char*)pt; // 强制类型转换, 按字节读
for (int i = 0; i < sizeof(Test); ++i) {
printf("%x ", *(ppt + i));
}
cout << endl;
// 1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f
return 0;
}
再进行整体对齐:这个 struct 类型所需字节为 24 字节,恰好是 n 的倍数,无须在尾部额外填充。
内存排列如下图所示:
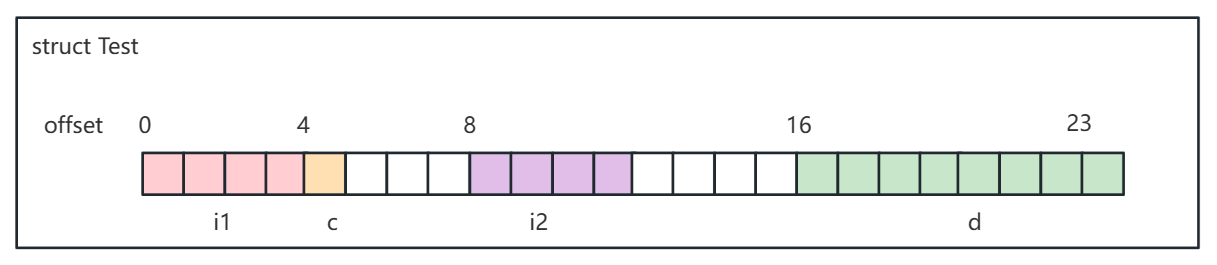
其中白色格子代表填充,其内容是不确定的。
按十六进制输出:1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f
-
可以看到前面 4 字节是 1 0 0 0,是
i1 = 1; -
第 5 字节是 61,是
'a'的十六进制 ASCII 码; -
然后 6-7 字节是填充的内容,不确定的;
-
第 8-11 字节是 2 0 0 0,是
i2 = 2; -
第 12 - 15 字节是填充的内容,不确定的;
-
第 16-23 字节是
d = 1.25的底层二进制表示(怎么算的我也忘了好久了,参考神书《CSAPP:深入理解计算机系统》即可找回记忆)。
留下疑问
问:在自定义类型嵌套时,比如 Test1 嵌套正在 Test2 中,此时应该怎么进行内存对齐呢?
struct Test1
{
int i1;
char c;
int i2;
double d;
// 构造函数
Test1(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
struct Test2
{
Test1 t1;
int x;
};
答:先计算 Test1 所占字节大小 sizeof(Test1),然后继续按照上述基本原则计算 Test2 即可。如果是多重嵌套,那就递归找到那个成员全都是基本类型的 struct 开始计算,然后回溯。
问:继承体系中如何进行内存对齐?
struct A
{
int i;
char c1;
};
struct B: public A
{
char c2;
};
struct C: public B
{
char c3;
};
答:我也不会!我郁闷了,在我 64 位 Windows 操作系统 + gcc8.1.0 和 ubuntu18.04 + gcc7.5.0 上的运行结果都是 12!
但是我参考的一篇博客说,他的结果是 8 或 16!C++ 内存对齐 - tenos - 博客园 (cnblogs.com)
博客里说根据编译器类型拥有两种方式:先继承后对齐和先对齐后继承。
但是我无论按哪种方式,#pragma pack ()取 4 或 8,排列组合 2*2=4 种可能,我都算不出来 12!但是我能算出 8 和 16!
希望有朋友可以解答我的疑惑,万分感谢。
最后
如果本文对你有帮助,请点个赞吧。
有任何疑问,欢迎评论和我一起讨论。



评论区