


1. 论文简介
论文题目:MonoIndoor: Towards Good Practice of Self-Supervised Monocular Depth Estimation for Indoor Environments
Paper地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Ji_MonoIndoor_Towards_Good_Practice_of_Self-Supervised_Monocular_Depth_Estimation_for_ICCV_2021_paper.pdf
Paper类型:深度学习(自监督)
发表刊物:ICCV
发表时间:2019
2. Abstract
室内单目深度估计比室外更具挑战:
- 室内的深度范围在不同的帧之间变化很大,使得深度网络很难诱导出一致的深度线索,而室外的的最大距离基本上保持不变,因为最远处一般是天空,无论相机怎么移动,天空始终无穷远。(这里需要注意的是:室外深度估计一般会将深度约束在一定范围,比如[0.1, 100],所以无论怎么变化,无穷远处影响不大);
- 室内的图像序列之间包含更多的旋转运动,而室外主要是平移移动,比如说KITTI数据集。注意:旋转运动对于姿态网络是一种困难。
本文主要提出的方法,一篇半监督单目室内场景深度估计:
- 深度分解模块:将depth map分解成一个全局深度尺度因子和一个相对深度,这里比较重要的是深度尺度因子,用于自适应的适应训练过程中深度尺度的变化。
- 残差姿态估计模块:核心就是一次性完成source view到target view的工作,换成了几次迭代来完成,缓解旋转预测不准确的问题。

3. Abstract
深度估计的背景介绍,价值和意义。

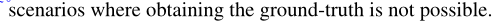
现有半监督方法的简单介绍,主要说明存在的问题:
- 性能上比不过监督方法;
- 室外比室内更好做半监督;

室内深度估计对比室外深度估计存在的两个关键挑战:
- 场景内的深度变化大,让深度网络在跨图像保持深度一致上存在困难;其实可以理解为,深度网络学习固定深度尺度比较好学习,当深度尺度各种变化时,它就很难拟合了。
- 针对姿态估计网络的,在半监督方法中,通常采用由源视角的图像投影(合成)到目标视角的图像,或者反过来。一般的做法是一次性根据相机内参,深度图,姿态网络估计的相对位姿来投影得到图像做loss,本文采用残差的方式,多阶段生成相对相机位姿阶段性合成图像,最终把所有合成图像加起来的到最终图像。类似一种软过度。
室内深度估计困难的根本原因是:人工手持相机捕获图像,或者MAVs方式,就会导致旋转。;

本文的框架以细节,前面已经有很详细的描述了:深度分解模块和残差姿态估计模块:
- 在深度分解模块中,我们将深度图分解为全局深度比例尺(用于当前图像)和相对深度图。深度尺度因子由深度网络中的一个额外分支单独预测。这样,深度网络具有更强的模型可塑性,能够适应训练过程中深度尺度的变化。
- 在残差位姿估计模块中,我们通过执行残差位姿估计以及初始大位姿预测来缓解旋转预测不准确的问题。这种残差方法可以更准确地计算光度损失,这反过来又可以更好地训练深度网络的模型。


3. Related Work
在本节中,回顾了单眼深度估计的监督和自监督方法。
3.1 Supervised Monocular Depth Estimation
早期的深度估计方法大多是有监督的。
Saxena等[30]用超像素特征和马尔可夫随机场(MRF)回归单幅图像的深度。
Eigen等[6]提出了第一个基于深度学习的单目深度估计方法,使用多尺度卷积神经网络(CNN)。后来的方法通过更好的网络架构[19]或通过更复杂的训练损失来提高深度预测的性能[21,8,41]。一些方法[363,34]依赖于两个网络,一个用于深度预测,另一个用于运动,在监督框架中模拟几何运动结构(SfM)或同步定位和映射(SLAM)。训练这些方法需要地面真相深度数据,而获取这些数据通常成本很高。还有一些方法采用传统的三维重建方法生成伪地真深度标签[23,22],如SfM[31]和SLAM[26],或3D电影[28]。这种方法具有更好的跨不同数据集的泛化能力,但不一定能达到手头数据集的最佳性能。

3.2 Self-Supervised Monocular Depth Estimation
由于自监督深度估计不需要使用地面事实进行训练,因此近年来受到了广泛的关注。沿着这条线,Garg等[9]提出了第一个自监督方法,使用立体图像之间的颜色一致性损失来训练单目深度模型。
Zhou等人[46]使用两个网络(即一个深度网络和一个姿态网络)来构建跨时间框架的光度损失。许多后续方法试图通过新的损失条款来改善自我监督。戈达尔等[11]在立体训练中引入了左右深度一致性损失。Bian等人[1]提出了时间深度一致性损失,以鼓励相邻帧具有一致的深度预测。Wang等[37]在训练过程中观察到了深度模型的递减问题,并提出了一种简单的归一化方法来对抗这种影响。Yin et al[42]和Zou et al[48]使用三个网络(即一个深度网络,一个姿态网络和一个额外流网络)来强制光流和密集深度之间的跨任务一致性。Wang等人[39]和Zou等人[47]利用循环神经网络(如LSTMs)来建模姿态网络和/或深度网络中的长期依赖关系。Tiwari等人[35]利用单目SLAM和自监督深度模型[12]组成了一个自改善环,以提高各自的性能。值得注意的是,Monodepth2[12]通过一组技术显著提高了以前的方法的性能:每像素最小光度损失来处理遮挡,自动掩蔽方法来掩盖静态像素,以及多尺度深度估计策略来缓解深度纹理复制问题。由于Monodepth2的良好性能,我们实现了基于Monodepth2的自监督深度估计框架,但对深度和位姿网络都做了重要的改变。

上述大多数方法仅在KITTI等室外数据集上进行评估。
一些最近的方法[45,44,2]集中在室内自监督深度估计。Zhou等人[45]提出了一种基于光流的训练范式,并通过预处理步骤去除所有具有“纯旋转”的图像对来处理较大的旋转运动。Zhao等[44]采用几何增广策略,通过两视图三角剖分求解深度,然后使用三角剖分深度作为监督。Bian等[2]认为“训练时旋转表现为噪声”,并提出了一个整流步骤来去除连续帧之间的旋转。我们有一个类似[45]和[2]的观察,大的旋转会给网络带来困难。然而,我们采取了不同的策略。我们没有从训练数据中去除旋转,而是通过一种新的残差姿态模块逐步估计它们。这反过来又提高了深度预测。

4. Method
在本节中,我们将详细描述如何使用MonoIndoor执行自监督深度估计。
具体来说,我们首先介绍了自监督深度估计的背景。然后,我们描述了使用MonoIndoor预测深度的良好实践。
4.1 Self-Supervised Depth Estimation
半监督的核心思想(基于投影策略):
将自监督深度估计作为一种新的视图合成问题,通过训练一个模型来从源图像的不同视点预测目标图像。
利用深度图作为桥接变量对图像合成过程进行训练和约束。该系统既需要目标图像的预测深度图,也需要一对目标图像和源图像之间的估计相对位姿。
具体来说,给定目标图像It和另一个视图下的源图像It0,联合训练系统预测目标图像的密集深度图Dt和从目标到源的相对相机姿态Tt→t0。
公式(1)(2)就是投影中的两个核心公式,公式2将源图像投影到目标图像,公式(1)计算目标图像与投影图像直接的loss。
公式(3)是对公式(1)的具体展开,公式(4)是公式(2)的细节;
公式(5)是一个常用的损失函数。


深度一致损失,公式(7)。


现有的自监督深度估计方法在室外很好,室内不好。

4.2 Depth Factorization
这一段我觉得是特别重要,因为说明了室内场景与室外场景本质的不同。
本文使用Monodepth2作为backbone。
注意,最终的深度预测不是直接来自卷积层,而是经过一个sigmoid激活函数和一个线性缩放函数,如公式(8)所示。
在公式(8)中,a和b将深度图D限制在一定范围内,a表示最小深度值,b表示最大深度值。比如KITTI数据集,a被设置为0.1,b被设置为100。主要是因为室外场景相机最远点在天空,永远无限远,所以统一被设置为100。
但是,公式(8)不太适用于室内场景。因为随着场景的变化,深度变化时不一样的。比如说,浴室大概是[0.1, 3],而大厅一般为[0.1, 10]。
预设深度范围将作为一个不准确的引导,不利于模型捕获准确的深度尺度。
在室内场景中常见的快速尺度变化尤其如此。为了克服这个问题,我们提出了深度分解模块(参见图1),以相对深度图和全局比例因子的形式学习解纠缠表示。
我们使用Monodepth2[12]的深度网络来预测相对深度,并提出了一种自注意引导的尺度回归网络来预测当前视图的全局尺度因子(这一步应该是自适应策略)。


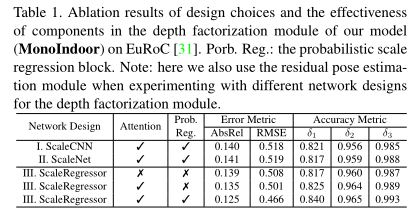
4.2.1 Scale Network
尺度网络本身是一个self-attention block,输入为encoder得到的特征,首先得到查询,键和值,接着查询和键结合后经过一个softmax,再和值结合,最后与输入的特征结合,经过1×1卷积输出一个全局深度尺度因子。


4.2.2 Probabilistic Scale Regression Head
为了预测全局尺度,高维特征图必须映射为单个正数。一种直接的方法是让网络直接回归得到尺度因子。然而,我们观察到使用这种方法训练是不稳定的。为了缓解这个问题,受[4]的启发,我们建议使用概率尺度回归头来估计这个连续值。给定一个全局尺度因子所处的最大边界,通过softmax(·)运算,从尺度网络eS的输出中计算出每个尺度s的概率。预测的全局尺度S计算为公式(11)。
通过这样做,回归问题可以通过基于概率分类的策略顺利解决(更多消融结果见第4.1.1节)。


4.2.3 Residual Pose Estimation
如3.1节所述,自监督深度估计建立在新的视图合成之上,这需要精确的深度图和相机姿态。估计准确的相对位姿是光度重投影损失的关键,因为不准确的位姿可能导致目标和源像素之间的错误对应,从而导致预测深度的问题。现有的方法大多使用一个独立的PoseNet来估计两幅图像之间的6自由度(DoF)姿态。在户外环境中(例如,像KITTI这样的驾驶场景),相对的相机姿势是相当简单的,因为汽车大部分是向前移动的,平移很大,但旋转很小。这意味着姿态估计通常不那么具有挑战性。相比之下,在室内环境中,序列通常是用手持设备(如Kinect)记录的,因此涉及到更复杂的自我运动以及更大的旋转运动。因此,姿态网络学习精确的摄像机姿态更加困难。

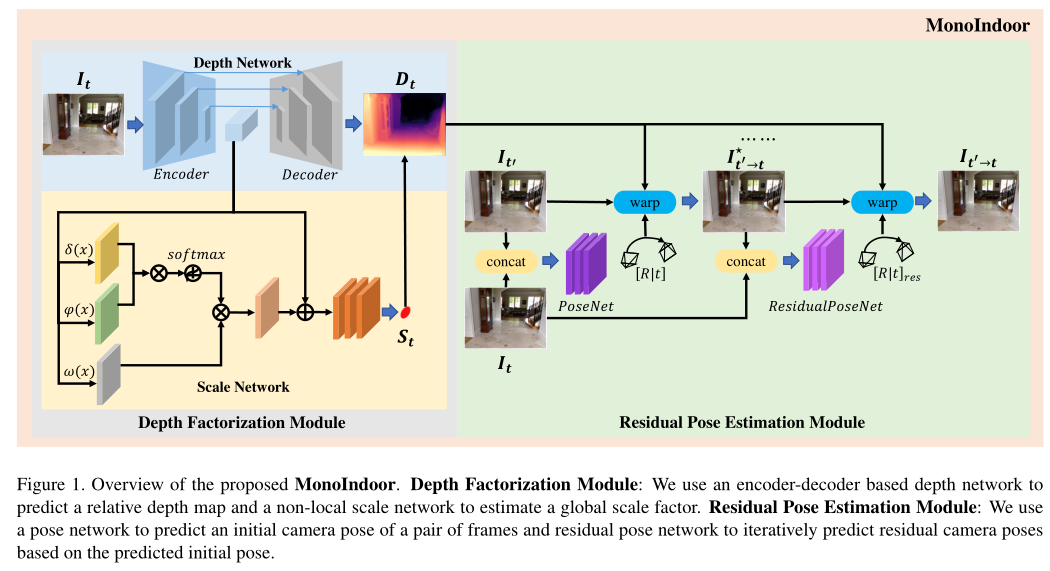
与现有方法[45,2]在数据预处理过程中专注于“去除”或“减少”旋转分量不同,我们提出了残差姿态估计模块,迭代学习目标与源图像之间的相对相机姿态(如图2所示)。
在第一阶段,姿态网络以目标图像It和源图像It0为输入,预测初始相机姿态Tt0→t,其中t0中的下标0表示还没有应用转换。然后根据式(2)对源图像进行双线性采样,重建虚拟视图It0→t,如果对应关系匹配准确,则期望它与目标图像相同。然而,由于不准确的姿态预测,情况不会如此。注意这里的转换定义为公式(12)。
第二阶段,我们利用残差姿态网络(见图1中的ResidualPoseNet),将目标图像和合成视图It0→t作为输入,输出残差相机姿态t res(t0→t)→t,表示合成图像It0→t相对于目标图像的相机姿态。现在,我们对合成图像使用公式(13)进行双线性采样得到新的合成视角。
后面可以继续迭代第二阶段。
最终的公式可以表达为公式(14),在获得多个残差姿态自后,总的相机姿态可以表达为所有残差姿态的求和,如公式(15)。
我猜想,公式(14)替代了公式(2)。



5. Experiments
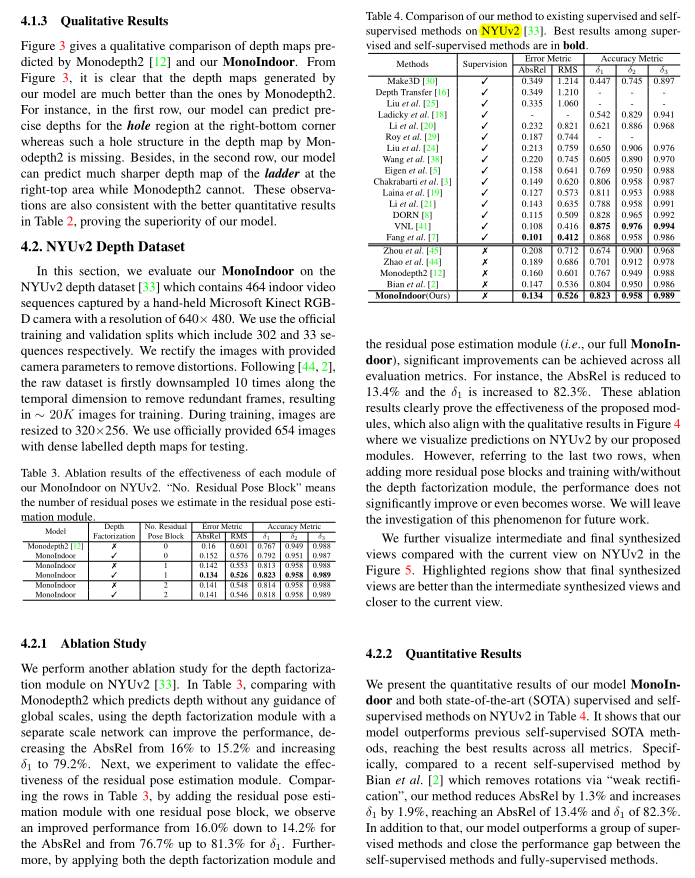
数据集:EuRocMAV,NYUv2,RGB-D 7-Scenes。

验证指标:常规的几个。

实现细节:Implementation Details
我们使用PyTorch[27]来实现我们的模型。在深度分解模块中,我们使用与[12]中相同的深度网络;对于规模网络,我们使用两个基本剩余块,然后是三个完全连接的层,中间是一个辍学层。退出率设置为0.5。在残差位姿模块中,我们让残差位姿网络使用一种通用的结构[12],由共享的姿态编码器和独立的姿态回归器组成。每个实验使用Adam[17]优化器训练40个epoch,前20个epoch的学习率设置为10−4,其余epoch的学习率降至10−5。平滑项τ和一致性项γ分别设为0.001和0.05。


6.1 EuRoC MA V Dataset






6. Conclusion
亮点:
- 本文对室内场景对比室外场景在做深度估计任务上存在的难点做了很好的分析,个人觉得很适合想做室内深度估计的同学阅读;
- 本文其实是针对无监督的两个核心:深度估计网络,姿态估计网络;深度估计网络对于深度尺度变化大时难以拟合,而姿态估计对于旋转问题很难拟合。因此提出了分别的针对方法。针对深度估计网络,进行因式分解,分别学习全局深度尺度和相对深度图;针对姿态估计网络,设计多阶段的残差学习软过度合成图像过程,替代一次性合成。
不足:
- 总体框架还是很不错,可惜的是自己的设计相对较少,backbone是monodepth2,尺度因子估计用的是self-attention module,大多是用的现有方法。
- 代码未公布,对于一些消融细节比较难确定是否有效。
- 多阶段残差学习是否真的有效,我不太确定。
7. 结语
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。



评论区